- Яндекс раскрыл алгоритм формирования быстрых ответов и проговорился про description
- 1 — Колдунщики Яндекса. Что это?
- 2 — Алгоритм Fact Snippet. Как формируются фактовые ответы
- 3 — Нейросуммаризация поиска. Сайты больше будут не нужны
- Интересный нюанс
- Выводы
- Yandex Y1: чего ждать вебмастерам, владельцам сайтов и SEO-специалистам
- Алгоритм Y1: перспективы для SEO-специалистов и вебмастеров
- Быстрые ответы made in Yandex
- Поиск внутри видео
- Оценка по отзывам
- Умная камера
- К чему приведёт Y1?
- Подводим итоги
Яндекс раскрыл алгоритм формирования быстрых ответов и проговорился про description
Для ряда поисковых запросов наличие страниц в поисковой выдаче не требуется.
Yandex раскрыл алгоритм формирования фактовых ответов, а еще проговорился про формирование description.
Как поисковая система формирует быстрые ответы?
Рассмотрим тему далее.
1 — Колдунщики Яндекса. Что это?
Что такое колдунщики Яндекса? Колдунщики — это элементы поисковой выдачи, которые отвечают на поисковый запрос прямо на странице с результатами поиска. Это может быть прогноз погоды, картинка, перевод слова и многое другое. В результате пользователь проводит быстрый поиск, и в большинстве из случаев не посещает сайты.
Пример колдунщика в поисковой выдаче:
В поисковой выдаче Google есть блоки с подобными ответами.
Еще поисковые системы совершенствуются, переходят от поиска по ключевым фразам к поиску по смыслам (алгоритм BERT).
В результате поисковые системы монополизируют трафик. Рекомендованный материал в блоге MegaIndex на тему монополизации трафика по ссылке далее — Аналитические данные о поисковой выдаче Google, которые могут изменить планы на продвижение.
На языке инженеров такие блоки называются блоками с фактовыми ответами.
Как такие блоки формируются, чем различаются и что важного произошло в этой области за последнее время?
2 — Алгоритм Fact Snippet. Как формируются фактовые ответы
Сначала были имплементированы блоки без интерактивных функций, то есть блоки без взаимодействий. Например:
Ответы на подобные запросы встречаются в поисковой выдаче с высокой частотой. В результате многие сайты потеряли трафик. Например, поисковый запрос:
Раньше трафик забирал 2ip. Теперь трафик забрал Yandex.
Рассмотрим детали. Весь процесс создания таких блоков в поисковой системе выглядел так:
- Специальные сотрудники анализировали наиболее популярные запросы, выбирали те, на которые можно найти короткий ответ. Так были охвачены наиболее популярные ключевые фразы;
- Затем были использованы толокеры. Сначала выдвигалась гипотеза. Затем отвечали толокеры. Адекватность ответов перепроверялась.
Затем система получила еще ряд улучшений.
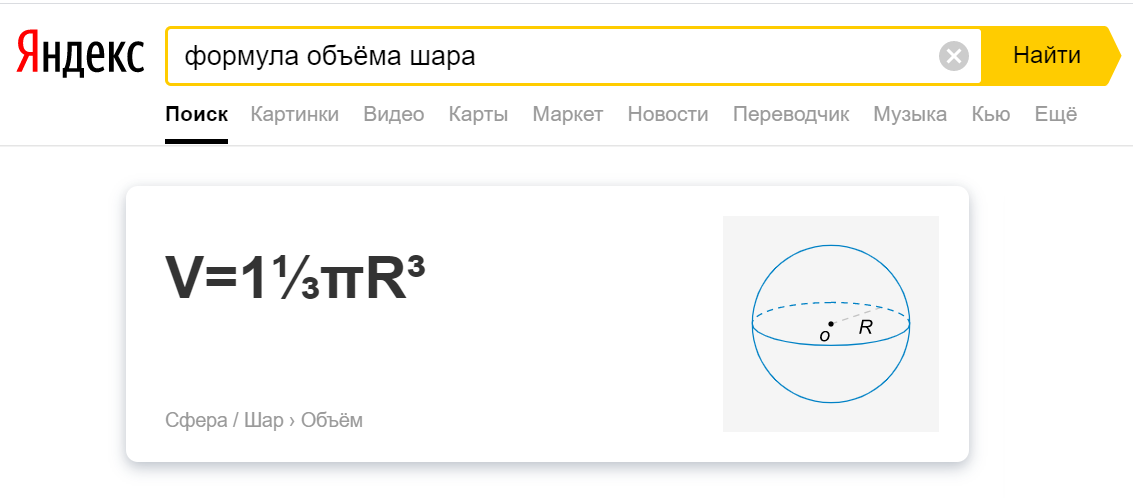
Был разработан алгоритм Fact Snippet. Сначала алгоритм должен был использовать текст из description. Имеется ввиду текст, который генерируется алгоритмом поисковой системы вне зависимости от фактического description. Но информативное описание страницы не во всех случаях является прямым ответом на вопрос.
Поэтому в Яндекс сделали так. Сначала нейросетевая модель была обучена на уже известных ответах. Затем происходит так — нейросетевая модель строит векторы ответов для найденных в поиске страниц и сравнивает их с вектором запроса.
Большинству запросов не требуется фактовый ответ. Поэтому в Yandex улучшили алгоритм для отсева нефактовых запросов. Задача была решена.
Дальше в Yandex поставили задачу по выходу за пределы фактов. Появился алгоритм Fact Snippet 2.
Пример ответа в поисковой выдаче:
Если упростить, то Fact Snippet 2.0 — это тот же Fact Snippet, но без требования найти исчерпывающий ответ.
В Fact Snippet 2.0 адаптированы оба этапа так, чтобы находить ответы на более широкий срез вопросов.
Такие ответы не претендуют на энциклопедическую полноту, но всё равно полезны. Иногда хорошие ответы есть в иных источниках. Например, на картах. К примеру, зачем предлагать адрес организации текстом, если можно показать интерактивную карту, номер телефона и отзывы. Проблему решает блендерный классификатор.
В результате еще больше ключевых фраз охвачены. В поисковой выдаче еще больше быстрых ответов. Но нет предела желанию монополизировать трафик. Алгоритм еще улучшили.
Переформулировки запросов. Часть поисковых запросов остались не охвачены. Существенная доля — таких ключевых фраз является переформулировками уже известных фраз. Например:
Данную задачу решает механизм поиска алиасов. Работает так:
- Берутся все запросы, на которые есть ответы;
- Преобразуются в векторы и кладутся в индекс k-NN. Применяется оптимизированная версия индекса HNSW, которая позволяет искать быстрее;
- Строятся векторы запросов, на которые нет ответа по прямому совпадению;
- Ищется топ N наиболее похожих запросов в k-NN;
- Далее топ прогоняется через катбустовый классификатор тройки: запрос пользователя, запрос из k-NN, ответ на запрос из k-NN;
- Если вердикт классификатора положительный — запрос считается алиасом запроса из k-NN, поисковая система может вернуть уже известный ответ.
Главная задача заключается в написании факторов классификатора. Самые сильные:
- Векторы запросов;
- Расстояния Левенштейна;
- Пословные эмбеддинги;
- Факторы на основе разнообразных колдунщиков по каждому из запросов;
- Расстояние между словами запросов.
Кстати определить смысловую близость запросов можно и другими способами. Например, если два запроса отличаются друг от друга одним словом, то как вариант можно проверить, как отличаются результаты поиска по этим запросам (посмотреть на число совпадающих ссылок в топе).
В быстром режиме искать алиасы не просто из-за ограничений по техническим ресурсам, потому применяют BERT. Сделали так:
- Собрали BERT-моделью очень много (сотни миллионов) искусственных оценок;
- Обучили на них более простую нейронную сеть DSSM, которая очень быстро работает в рантайме.
В результате с некоторой потерей точности удалось получить сильный фактор.
3 — Нейросуммаризация поиска. Сайты больше будут не нужны
Интересный нюанс
В ходе разбора работы алгоритма фактовых ответов Яндекс рассказал про формирование текста для сниппетов страниц. Поисковая система способна автоматически создавать текст для сниппета.
Как создается текст? Алгоритм ищет лучший фрагмент текста на странице. Применяется модель CatBoost, которая оценивает близость фрагмента текста и запроса.
По сути алгоритм нацелен на то, чтобы выдать в тексте сниппета фактический ответ.

Здесь открывается поле для манипуляций. Значение для сниппета задается через description. Например, для сайта indexoid:
Но прописывать значение для description является необязательным условием для индексации страницы.
В результате поисковой есть вариант:
- Создать группы страниц без описания. Например, копии страниц лидеров поиска;
- Выявить какой именно фрагмент текста является лучшим ответом на ключевую фразу;
- Применить полученные данные в текстовой оптимизации страниц сайта.
Еще пример:
- Создать группы страниц без описания. Например, группы страниц на одну тему, но с разным текстом;
- Выявить какой именно фрагмент текста является лучшим ответом на ключевую фразу;
- Применить полученные данные в текстовой оптимизации страниц сайта.
По сути, поисковый алгоритм сравнивает два вектора: вектор запроса и вектор текста документа.
Чем ближе векторы в многомерном пространстве, тем ближе смыслы текстов по данным поисковой системы.
Выводы
В поисковой системе Yandex переходят от поиска страниц по ключевым фразам к поиску ответов. В результате будет реклама поисковой системы и прямые ответы, а трафик на страницы сайтов будет идти лишь через навигационные ключевые фразы.
В поисковой системе Google двигаются аналогичным образом. Рекомендованный материал в блоге MegaIndex на тему поиска по смыслу по ссылке далее — ГУГЛ БЕРТ.
Fact Snippet работает в два этапа. В Fact Snippet 2 принцип подобный, но есть нюансы. Этапы в Fact Snippet следующие:
- На первом этапе с помощью лёгкой модели оценивается фактовость запроса, иными словами проверяется фактовый ответ или нет;
- Если да, ответ выводится в поисковой выдаче.
Для Fact Snippet 2.0 адаптированы оба этапа так, чтобы искать решение по более широкому срезу вопросов. Такие ответы не претендуют на энциклопедическую полноту, но всё равно полезны.
Сниппеты сайтов влияют на кликовые факторы.
Для увеличения кликабельности в поисковой выдаче следует создавать привлекательный текст, и для решения задачи по созданию кликабельных сниппетов можно использовать анализ сниппетов страниц конкурентных сайтов.
Что вы думаете о тенденциях? Какие шаги предпринимаете? Напишите в комментариях.
Источник
Yandex Y1: чего ждать вебмастерам, владельцам сайтов и SEO-специалистам
Здравствуйте, дамы и господа, 10.06.2021 г. Яндекс представил глобальное обновление поисковой системы — Y1. Давайте в пределах статьи рассмотрим, чего стоит ждать от нового обновления, а также о том, как это повлияет на сайты, участвующие в поиске Яндекс.
Почитать про Y1 вы можете в блоге вебмастера от Яндекс, там немного сказано об обновлении, я же попробую рассказать, чего ждать без прикрас.
Алгоритм Y1: перспективы для SEO-специалистов и вебмастеров
Итак, новое обновление презентуется, как система, которая должна сократить время между запросом пользователя и поиском ответа на него. Вроде цель хорошая, но несколько вещей вызывают сомнения. Давайте посмотрим на то, что сделал Яндекс.
Быстрые ответы made in Yandex
Первым нововведением стала система быстрых ответов. Нет, мы видели её и раньше. И в Яндекс, и в Google, но у Яндекс это был только эксперимент, теперь же это будет повсеместной практикой.
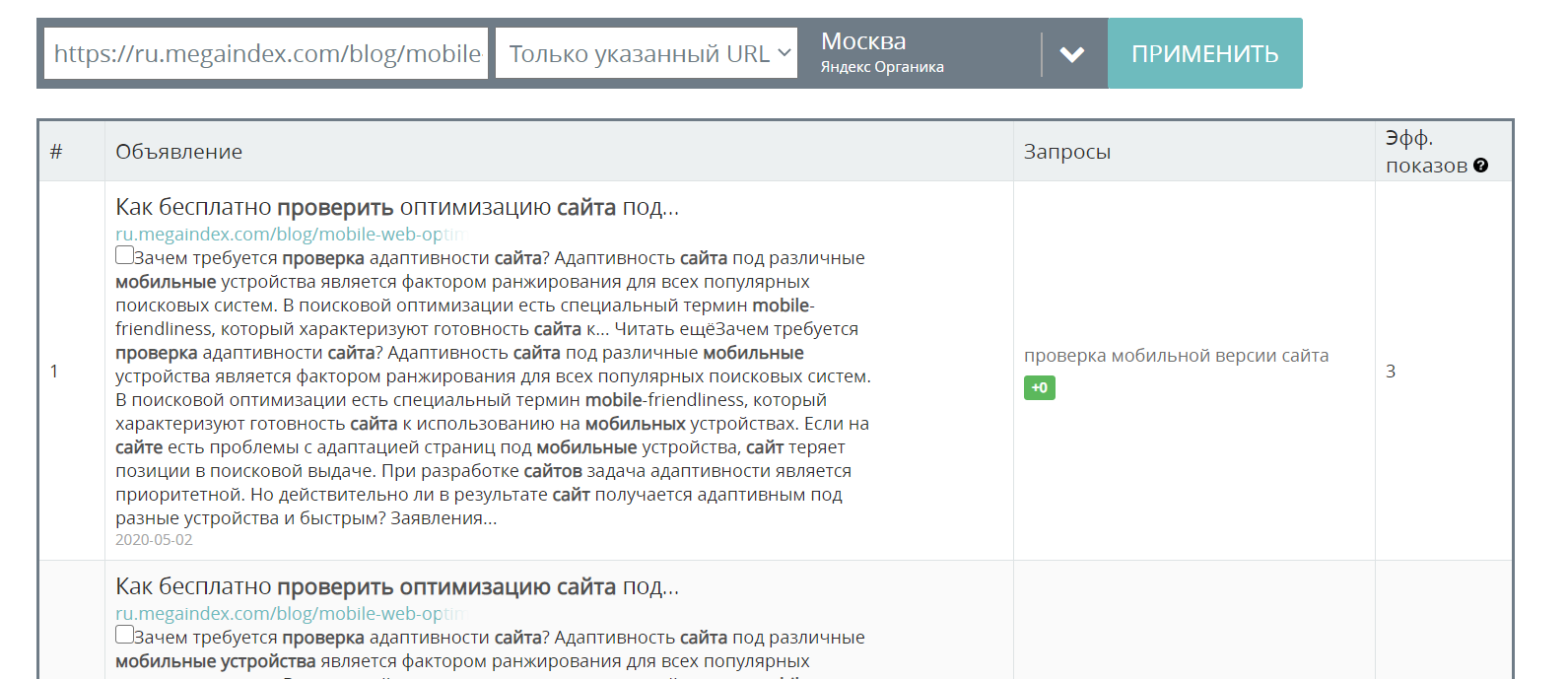
Но данная система ещё несовершенна. К примеру, вот этот вариант быстрого ответа не отвечает на вопрос от слова совсем.
![]()
Впрочем, уверен, Яндекс это доработает со временем. Так что скоро выдача будет полностью монополизирована Яшей. На многие вопросы Яндекс вполне корректно даёт быстрые ответы.
Но что же это предвещает владельцам сайтов и SEO- специалистам?
В общем, за этими блоками быстрых ответов я слежу уже давно. И информация в них меняется с невероятной скоростью. Иногда по паре раз за день. В процессе моих наблюдений однозначного вывода, как повлиять на попадание в быстрые ответы, не выработалось, пока только предположения.
На это влияют поведенческие факторы, семантическое ядро, а также сам сайт: его «вес», популярность, ИКС, количество посетителей.
Но больше всего влияет семантика. Например, по запросу «дроп-домен» одно время в блоке быстрых ответов был мой сайт.
![]()
Но сейчас там известный хостинг и регистратор доменных имён.
![]()
Но самое смешное, если убрать дефис и написать «дроп домен», то в блоке быстрых ответов будет Хабр.
![]()
Так что прихожу к выводу, что больше всего влияет семантика. Даже наличие дефиса может изменить сайт в блоке быстрых ответов.
Так что теперь выдача по информационным запросам будет выглядеть примерно так:
![]()
И даже добавление региональности в запрос будет серьёзно изменять быстрый ответ, даже если суть вопроса при этом не меняется.
![]()
Так что нам это говорит?
Во-первых, начнётся серьёзная битва за блок быстрых ответов в плане информационных «околокоммерческих запросов». Блок быстрых ответов заметен на фоне остальных сайтов в выдаче, соответственно, SEO- специалисты не смогут это игнорировать.
Во-вторых, региональность запроса влияет на быстрый ответ, на чём можно играть, добавляя, например, региональность в семантику.
В третьих, по сути, любой «хвост» в запросе будет влиять на суть быстрого ответа.
![]()
Пока трудно сказать, как это будет работать, система быстрых ответов Y1 ещё сыровата, потому требуется больше экспериментов. И раз система ещё не устаканилась, нужно ждать доработок, она ещё может серьёзно измениться.
В общем, пока что только анонс, дабы быть наготове. Ничего объективно и с «пруфами» утверждать не могу.
Но чего ждать вебмастерам, блогерам и прочим владельцам информационных ресурсов? Всё просто: блок ответов очень заметен на фоне органической выдачи, те, кто туда попадёт, теперь будут получать больше потенциального трафика.
Но что будет в случае, если блок ответа полностью отвечает на вопрос?
![]()
Тогда всё очень просто: получив ответ, пользователь не перейдёт на ваш сайт. Ему это не нужно, он уже узнал, что хотел. Соответственно, вебмастер не получит денег за просмотр рекламы или с реферальной программы, ибо на его сайт так и не зашли.
В общем, претензии те же, что и в своё время были к быстрым ответам от Google. Яндекс берёт информацию с чьего-либо сайта, показывает на своей первой страницы, получает деньги за рекламу. Но владелец сайта, который данную информацию подготовил, не получает ничего: ни трафика, ни денег с монетизации.
По некоторым информационным запросам Яша уже давно выдачу монополизировал, раскидав там колдунщики, которые серьёзно повлияли на трафик сайтов. Но теперь в этой сфере присутствуют ещё и быстрые ответы. И если вы в них не попадёте, то трафик упадёт ещё больше.
![]()
Если раньше человек мог пролистать колдунщики и перейти в органику, то сейчас видит и быстрый ответ, который может находиться выше всех. И высока вероятность, что выдачу до вашего сайта просто не пролистают, а остановятся на быстром ответе.
Может, для людей наличие быстрых ответов хорошо, но для владельцев сайтов это не лучшая перспектива. Теперь многие сайты в поисковой выдаче станут ещё менее заметными.
Ну и видео с презентацией Y1. Интересно, почему не на Дзен разместили? А, ну да, проблемы со встраиванием на сайты.
Это чисто коммерческое видео, но в нём вполне ясно сказано: Яндекс хочет, чтобы люди не тратили время на сайты, а получали всё сразу на главной странице Яши. Выводы, дорогие вебмастера, делайте сами.
Поиск внутри видео
Также добавился поиск внутри видео, который должен позволить быстрее находить нужные отрезки в видео, дабы человек не тратил время на прокрутку и тому подобное. Не знаю, будет ли работать только с сервисами Яндекс. Вполне возможно, что YouTube и другие сервисы тоже будут учтены.
Но пока что мне не удалось проверить, как работает данная система. Впрочем, в выдаче встречаются не только видео с Дзен и Эфира.
![]()
Кажется, пока что это ещё не работает, когда прогонят кучу видео через Толокеров и научат нейросеть, будет нормально.
Какие-либо выводы делать ещё рано. Но если судить по рекомендациям, то прописывать таймкоды с соответствующей семантикой под видео, а также размещать видео в теле статьи — хорошая идея.
Оценка по отзывам
Эту часть изучил меньше всего. Но как утверждает Яндекс, теперь все отзывы будут превращаться в сводную оценку. Алгоритмы Яндекс на основе кучи «честных и ненакрученных» отзывов будут давать оценку заведениям, разнообразным местам.
Пока тоже стоит присмотреться, выводы делать ещё рано. Я не слишком сильно вдавался в данную тему, пока нужно просто наблюдать.
Умная камера
Теперь умная камера сможет распознавать товары, выдавать сразу цены. Конечно же, высока вероятность, что это будет касаться больше Яндекс Маркет а , а не сторонних сайтов, но посмотрим.
Пока что Яндекс заявляет, что для работы умного поиска можно ввести соответствующую разметку, которая позволит умному поиску брать информацию с вашего сайта и анализировать изображение вместе с данными об объекте на сайте. Например, если человек попробует узнать, что за бабочка, то сможет с помощью умной камеры получить о ней информацию.
Также можно выполнять поиск товара по изображению с помощью умной камеры, вместе с найденным изображением будет отображаться цена, характеристики и другая информация.
Можете об этом посмотреть на страниц е с презентацией Y1 .
Данная технология тоже пока мне доподлинно неизвестна, но посмотрим, во что её превратят чуть позже.
К чему приведёт Y1?
Итак, быстрые ответы, которые находят информацию и дают её в обход сайта, умные камеры, отзывы, поиск внутри видео. Яндекс создаёт экосистему, сложную и довольно интересную. Но она будет явно не в пользу тех, кто создаёт контент.
Фактически первым этапом были колдунщики, разнообразные сервисы Яндекс вроде Дзен и Знатоки. Это позволило частично исключить многие сайты из выдачи и занять Яндекс целую нишу.
Теперь второй этап — постепенное замещение контент-мейкеров нейросетями. Да, этот процесс затянется, нейросеть навряд ли сможет самостоятельно писать сложные технические тексты, проводить полноценную аналитику. Но это дело времени.
![]()
Алгоритм YaLM упорно учится писать тексты. И скоро вместо быстрых ответов, взятых с разных сайтов, будут быстрые ответы, написанные данным алгоритмом на основе анализа нейросетью тысяч других сайтов.
Это позволит выбросить «нахлебников» из поиска и не делиться с ними. Соответственно, со временем этот алгоритм сумеет писать даже новости, анализировать и обрабатывать информацию из видео и делать, например, рецензии к сериалам.
До этого ещё далеко, но это, к чему, похоже, стремится Яндекс. Постепенно поисковая система перестаёт быть прослойкой между пользователями и сайтами, а сама становится единоличным владельцем контента.
В принципе, вполне логичная эволюция, так что не удивительно, что это происходит.
Так что SEO- специалистов и маркетологов в ближайшее время ждут интересные приключения. Рано ещё говорить о том, как будет в итоге выглядеть Y1, эту систему ждёт множество доработок. Но битва за блоки ответов не заставит себя ждать, в этом я уверен, ибо выбора не будет.
В общем, станет сложнее жить, это очевидно.
Подводим итоги
Последние годы что Яндекс, что Google всё больше трафика перетягивают на себя. Вокруг агрегаторы, крупные экосистемы, а также огромные бюджеты. Небольшим интернет-магазинам и сравнительно небольшим сайтам всё сложнее жить в эпоху корпораций и монополий.
Яндекс потихоньку отобьёт трафик у таких сайтов, ведь всю информацию можно будет получить прямо на первой странице выдачи. Так что остаётся только с интересом наблюдать, как ситуация будет развиваться дальше.
На этой ноте с вами прощаюсь, желаю успехов!
Насколько публикация полезна?
Нажмите на звезду, чтобы оценить!
Средняя оценка 5 / 5. Количество оценок: 14
Источник



