- pandas fillna not working
- 5 Answers 5
- Not the answer you’re looking for? Browse other questions tagged python pandas or ask your own question.
- Linked
- Related
- Hot Network Questions
- Subscribe to RSS
- BUG: fillna with inplace does not work with multiple columns selection by loc #14858
- Comments
- hiiwave commented Dec 11, 2016
- Code Sample, a copy-pastable example if possible
- Problem description
- Comparison (1)
- Comparison (2)
- Expected Output of the first code sample
- Output of pd.show_versions()
- Основы Pandas №3 // Важные методы форматирования данных
- Merge в pandas («объединение» Data Frames)
- Как делается merge?
- Способы объединения: inner, outer, left, right
- Merge в pandas. По какой колонке?
- Сортировка в pandas
- reset_index()
- Fillna
- Проверьте себя
- Решение задания №1
- Решение задания №2
- Итого
- Python | Pandas DataFrame.fillna (), чтобы заменить нулевые значения в dataframe
pandas fillna not working
I have a dataframe with nans in it:
I have another dataframe with values in it:
Unfortunately, df.fillna does not appear to be working for me:
Why is this happening? I am on pandas 0.13.1

5 Answers 5
you need inplace

You need to assign the value df = df.fillna( t )

df = df.replace(np.nan, 0) #or any other value you deem fit
df.replace(np.nan, 0) or df.fillna(0) threw me off when I applied certain str.replace()-operations right after Na-operations.. so watch out for your order of commands -> first str.replace() than fillna()
You have two options:
1) Specific for each column
2) For the entire dataframe

Check this why fillna() while iterating over columns does not work. Create a DataFrame with columns and check the output of following:
Earlier one does not throw an error but was not filling NA values. Commented lines seem to be working.

Not the answer you’re looking for? Browse other questions tagged python pandas or ask your own question.
Linked
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
site design / logo © 2021 Stack Exchange Inc; user contributions licensed under cc by-sa. rev 2021.10.15.40479
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Источник
BUG: fillna with inplace does not work with multiple columns selection by loc #14858
Comments
hiiwave commented Dec 11, 2016
Code Sample, a copy-pastable example if possible
Problem description
It’s expected to modify the Nan to -1 but it does NOT.
Please see the following comparisons.
Comparison (1)
On contrary, the following codes behave as expected.
(The only difference is selection by iloc or by loc)
Comparison (2)
When only one column is selected with loc, it behaves properly.
Expected Output of the first code sample
Output of pd.show_versions()
pandas: 0.19.1
nose: None
pip: 9.0.1
setuptools: 27.2.0
Cython: None
numpy: 1.11.2
scipy: 0.18.1
statsmodels: None
xarray: None
IPython: 5.1.0
sphinx: None
patsy: None
dateutil: 2.6.0
pytz: 2016.10
blosc: None
bottleneck: None
tables: 3.3.0
numexpr: 2.6.1
matplotlib: 1.5.3
openpyxl: None
xlrd: None
xlwt: None
xlsxwriter: None
lxml: None
bs4: None
html5lib: None
httplib2: None
apiclient: None
sqlalchemy: None
pymysql: None
psycopg2: None
jinja2: 2.8
boto: None
pandas_datareader: None
The text was updated successfully, but these errors were encountered:
Источник
Основы Pandas №3 // Важные методы форматирования данных
Это третья часть руководства по pandas, в которой речь пойдет о методах форматирования данных, часто используемых в проектах data science: merge , sort , reset_index и fillna . Конечно, есть и другие, поэтому в конце статьи будет шпаргалка с функциями и методами, которые также могут пригодиться.
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Merge в pandas («объединение» Data Frames)
В реальных проектах данные обычно не хранятся в одной таблице. Вместо нее используется много маленьких. И на то есть несколько причин. С помощью нескольких таблиц данными легче управлять, проще избегать «многословия», можно экономить место на диске, а запросы к таблицам обрабатываются быстрее.
Суть в том, что при работе с данными довольно часто придется вытаскивать данные из двух и более разных страниц. Это делается с помощью merge .
Примечание: хотя в pandas это называется merge , метод почти не отличается от JOIN в SQL.
Рассмотрим пример. Для этого можно взять DataFrame zoo (из предыдущих частей руководства), в котором есть разные животные. Но в этот раз нужен еще один DataFrame — zoo_eats , в котором будет описаны пищевые требования каждого вида.
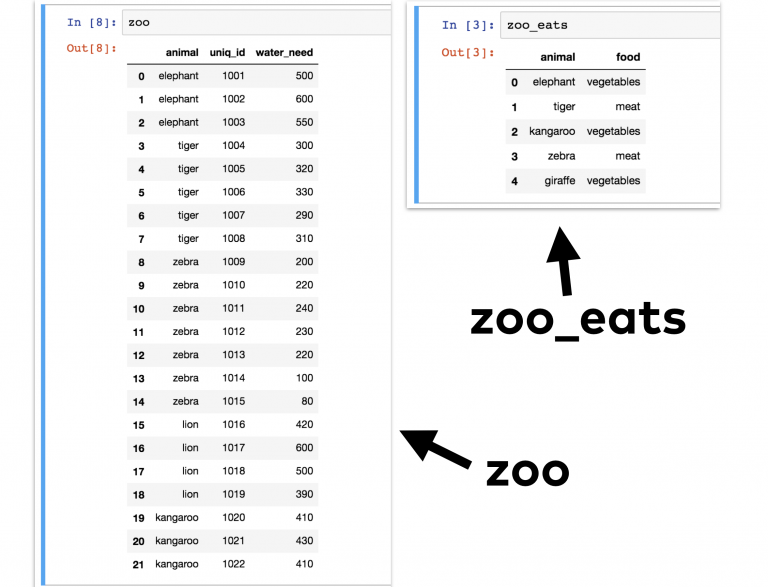
Теперь нужно объединить два эти Data Frames в один. Чтобы получилось нечто подобное:
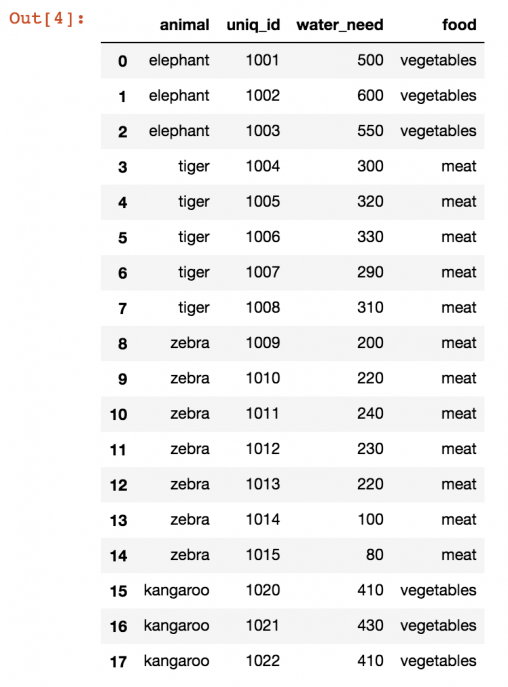
В этой таблице можно проанализировать, например, сколько животных в зоопарке едят мясо или овощи.
Как делается merge?
В первую очередь нужно создать DataFrame zoo_eats , потому что zoo уже имеется из прошлых частей. Для упрощения задачи вот исходные данные:
О том, как превратить этот набор в DataFrame, написано в первом уроке по pandas. Но есть способ для ленивых. Нужно лишь скопировать эту длинную строку в Jupyter Notebook pandas_tutorial_1 , который был создан еще в первой части руководства.
И вот готов DataFrame zoo_eats .
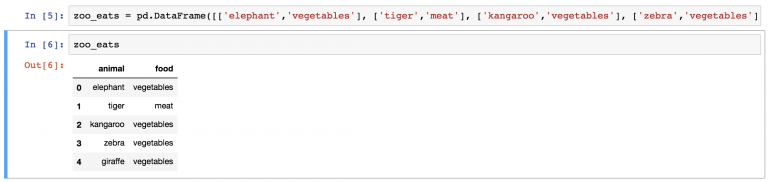
Теперь пришло время метода merge:
(А где же все львы? К этому вернемся чуть позже).
Это было просто, не так ли? Но стоит разобрать, что сейчас произошло:
Сначала был указан первый DataFrame ( zoo ). Потом к нему применен метод .merge() . В качестве его параметра выступает новый DataFrame ( zoo_eats ). Можно было сделать и наоборот:
Это то же самое, что и:
Разница будет лишь в порядке колонок в финальной таблице.
Способы объединения: inner, outer, left, right
Базовый метод merge довольно прост. Но иногда к нему нужно добавить несколько параметров.
Один из самых важных вопросов — как именно нужно объединять эти таблицы. В SQL есть 4 типа JOIN.
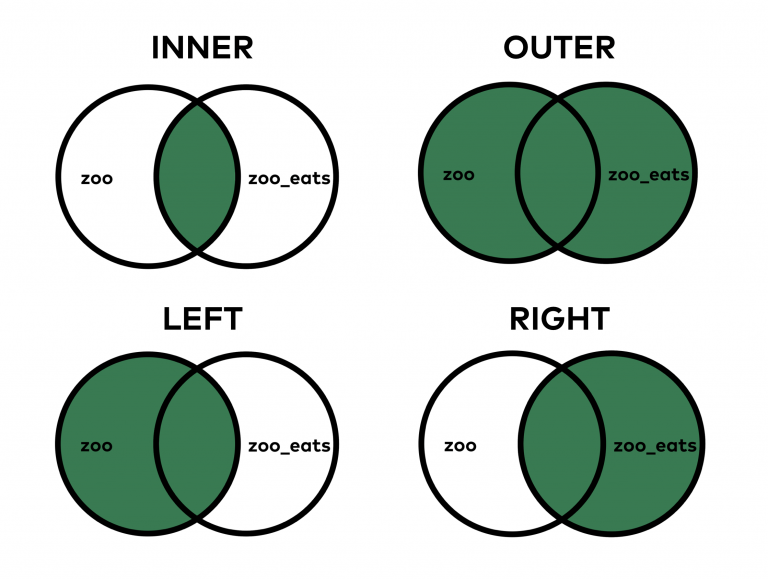
В случае с merge в pandas в теории это работает аналогичным образом.
При выборе INNER JOIN (вид по умолчанию в SQL и pandas) объединяются только те значения, которые можно найти в обеих таблицах. В случае же с OUTER JOIN объединяются все значения, даже если некоторые из них есть только в одной таблице.
Конкретный пример: в zoo_eats нет значения lion . А в zoo нет значения giraffe . По умолчанию использовался метод INNER, поэтому и львы, и жирафы пропали из таблицы. Но бывают случаи, когда нужно, чтобы все значения оставались в объединенном DataFrame. Этого можно добиться следующим образом:
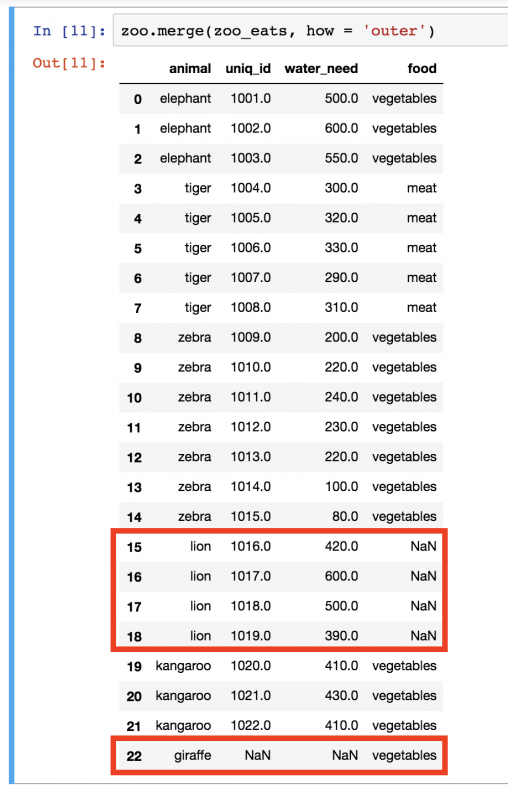
В этот раз львы и жирафы вернулись. Но поскольку вторая таблица не предоставила конкретных данных, то вместо значения ставится пропуск ( NaN ).
Логичнее всего было бы оставить в таблице львов, но не жирафов. В таком случае будет три типа еды: vegetables , meat и NaN (что, фактически, значит, «информации нет»). Если же в таблице останутся жирафы, это может запутать, потому что в зоопарке-то этого вида животных все равно нет. Поэтому следует воспользоваться параметром how=’left’ при объединении.
Теперь в таблице есть вся необходимая информация, и ничего лишнего. how = ‘left’ заберет все значения из левой таблицы ( zoo ), но из правой ( zoo_eats ) использует только те значения, которые есть в левой.
Еще раз взглянем на типы объединения:
Примечание: «Какой метод merge является самым безопасным?» — самый распространенный вопрос. Но на него нет однозначного ответа. Нужно решать в зависимости от конкретной задачи.
Merge в pandas. По какой колонке?
Для использования merge библиотеке pandas нужны ключевые колонки, на основе которых будет проходить объединение (в случае с примером это колонка animal ). Иногда pandas не сможет распознать их автоматически, и тогда нужно указать названия колонок. Для этого нужны параметры left_on и right_on .
Например, последний merge мог бы выглядеть следующим образом:
Примечание: в примере pandas автоматически нашел ключевые колонки, но часто бывает так, что этого не происходит. Поэтому о left_on и right_on не стоит забывать.
Merge в pandas — довольно сложный метод, но остальные будут намного проще.
Сортировка в pandas
Сортировка необходима. Базовый метод сортировки в pandas совсем не сложный. Функция называется sort_values() и работает она следующим образом:

Примечание: в прошлых версиях pandas была функция sort() , работающая подобным образом. Но в новых версиях ее заменили на sort_values() , поэтому пользоваться нужно именно новым вариантом.
Единственный используемый параметр — название колонки, water_need в этом случае. Довольно часто приходится сортировать на основе нескольких колонок. В таком случае для них нужно использовать ключевое слово by :

Примечание: ключевое слово by можно использовать и для одной колонки zoo.sort_values(by = [‘water_need’] .
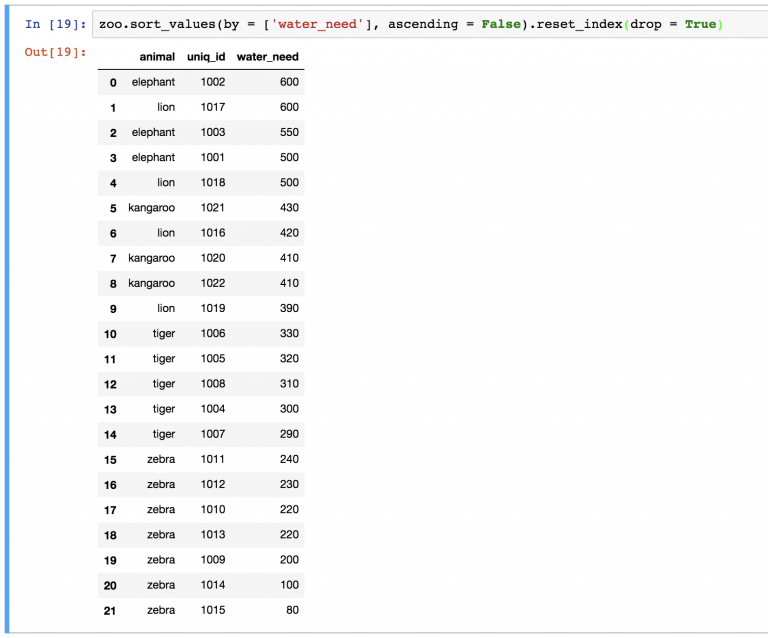
sort_values сортирует в порядке возрастания, но это можно поменять на убывание:
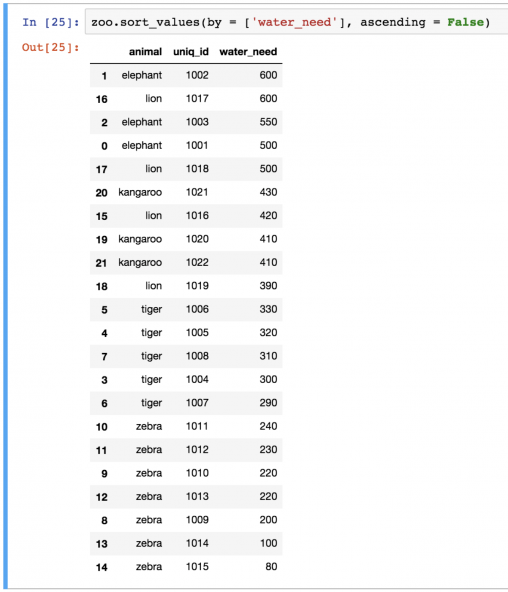
reset_index()
Заметили ли вы, какой беспорядок теперь в нумерации после последней сортировки?
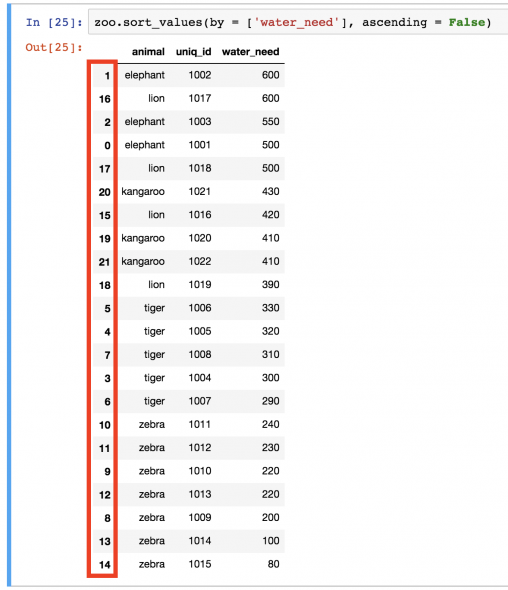
Это не просто выглядит некрасиво… неправильная индексация может испортить визуализации или повлиять на то, как работают модели машинного обучения.
В случае изменения DataFrame нужно переиндексировать строки. Для этого можно использовать метод reset_index() . Например:
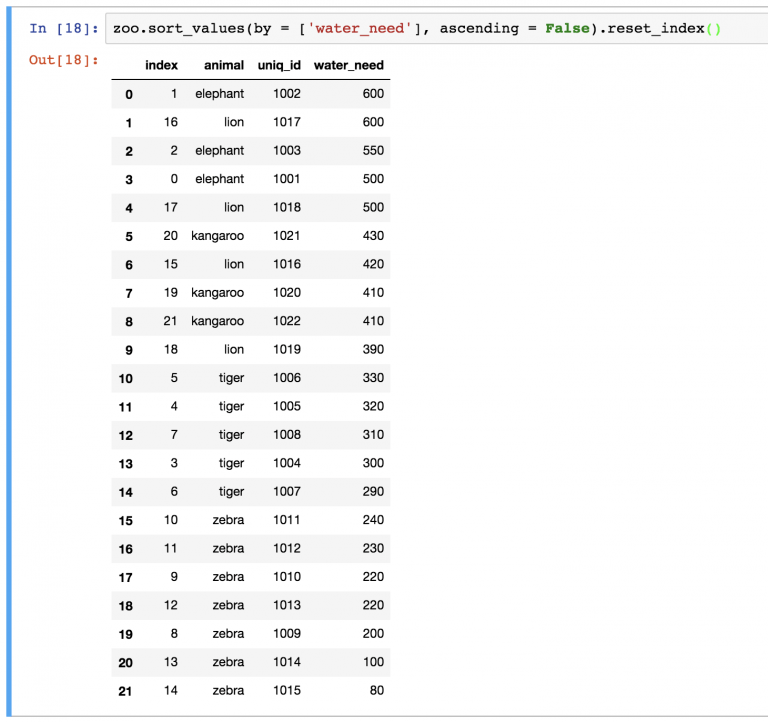
Можно заметить, что новый DataFrame также хранит старые индексы. Если они не нужны, их можно удалить с помощью параметра drop=True в функции:
Fillna
Примечание: fillna — это слова fill( заполнить) и na(не доступно).
Запустим еще раз метод left-merge:
Это все животные. Проблема только в том, что для львов есть значение NaN . Само по себе это значение может отвлекать, поэтому лучше заменять его на что-то более осмысленное. Иногда это может быть 0 , в других случаях — строка. Но в этот раз обойдемся unknown . Функция fillna() автоматически найдет и заменит все значения NaN в DataFrame:
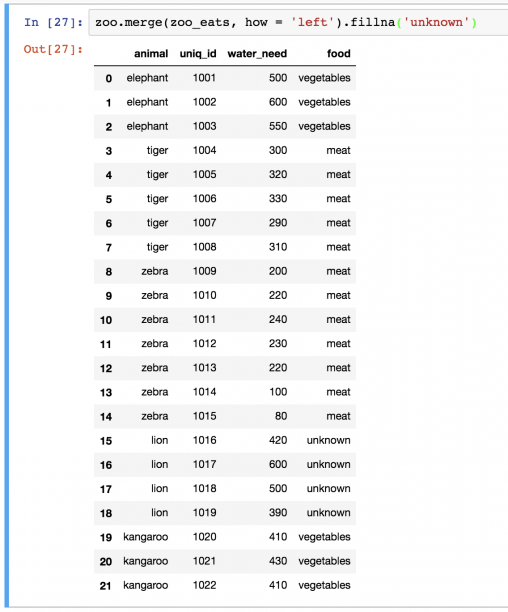
Примечание: зная, что львы едят мясо, можно было также написать zoo.merge(zoo_eats, how=’left’).fillna(‘meat’) .
Проверьте себя
Вернемся к набору данных article_read .
Примечание: в этом наборе хранятся данные из блога о путешествиях. Загрузить его можно здесь. Или пройти весь процесс загрузки, открытия и установки из первой части руководства pandas.
Скачайте еще один набор данных: blog_buy . Это можно сделать с помощью следующих двух строк в Jupyter Notebook:
Набор article_read показывает всех пользователей, которые читают блог, а blog_buy — тех, купил что-то в этом блоге за период с 2018-01-01 по 2018-01-07.
- Какой средний доход в период с 2018-01-01 по 2018-01-07 от пользователей из article_read ?
- Выведите топ-3 страны по общему уровню дохода за период с 2018-01-01 по 2018-01-07 . (Пользователей из article_read здесь тоже нужно использовать).
Решение задания №1
Средний доход — 1,0852
Для вычисления использовался следующий код:

Примечание: шаги использовались, чтобы внести ясность. Описанные функции можно записать и в одну строку.`
- На скриншоте также есть две строки с импортом pandas и numpy, а также чтением файлов csv в Jupyter Notebook.
- На шаге №1 объединены две таблицы ( article_read и blog_buy ) на основе колонки user_id . В таблице article_read хранятся все пользователи, даже если они ничего не покупают, потому что ноли ( 0 ) также должны учитываться при подсчете среднего дохода. Из таблицы удалены те, кто покупали, но кого нет в наборе article_read . Все вместе привело к left-merge.
- Шаг №2 — удаление ненужных колонок с сохранением только amount .
- На шаге №3 все значения NaN заменены на 0 .
- В конце концов проводится подсчет с помощью .mean() .
Решение задания №2
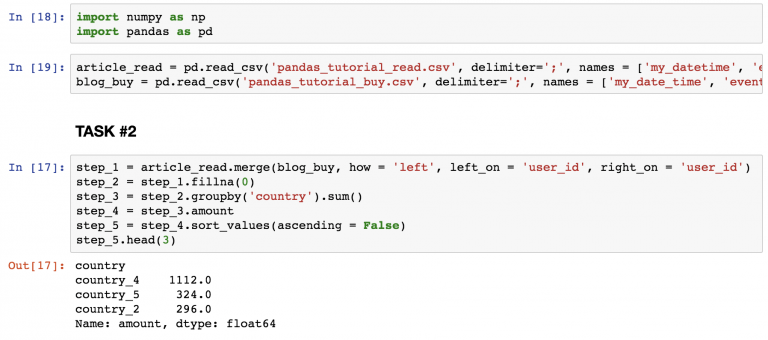
Найдите топ-3 страны на скриншоте.
- Тот же метод merge , что и в первом задании.
- Замена всех NaN на 0 .
- Суммирование всех числовых значений по странам.
- Удаление всех колонок кроме amount .
- Сортировка результатов в убывающем порядке так, чтобы можно было видеть топ.
- Вывод только первых 3 строк.
Итого
Это был третий эпизод руководства pandas с важными и часто используемыми методами: merge, sort, reset_index и fillna .
Источник
Python | Pandas DataFrame.fillna (), чтобы заменить нулевые значения в dataframe
Python — отличный язык для анализа данных, в первую очередь благодаря фантастической экосистеме пакетов Python, ориентированных на данные. Pandas — один из таких пакетов, который значительно упрощает импорт и анализ данных.
Иногда файл CSV имеет нулевые значения, которые позже отображаются как NaN в кадре данных. Подобно тому, как метод pandas dropna() управляет и удаляет значения Null из фрейма данных, fillna() управляет и позволяет пользователю заменять значения NaN на свои собственные значения.
Синтаксис:
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
Параметры:
value : Static, dictionary, array, series or dataframe to fill instead of NaN.
method : Method is used if user doesn’t pass any value. Pandas has different methods like bfill , backfill or ffill which fills the place with value in the Forward index or Previous/Back respectively.
axis: axis takes int or string value for rows/columns. Input can be 0 or 1 for Integer and ‘index’ or ‘columns’ for String
inplace: It is a boolean which makes the changes in data frame itself if True.
limit : This is an integer value which specifies maximum number of consequetive forward/backward NaN value fills.
downcast : It takes a dict which specifies what dtype to downcast to which one. Like Float64 to int64.
**kwargs : Any other Keyword arguments
Для ссылки на CSV-файл, используемый в коде, нажмите здесь .
Пример № 1: Замена значений NaN статическим значением.
Перед заменой:
# импорт модуля панд
import pandas as pd
# создание фрейма данных из CSV-файла
nba = pd.read_csv( «nba.csv» )
Выход:

После замены:
В следующем примере все пустые значения в столбце «Колледж» были заменены на строку «Нет колледжа». Сначала импортируется фрейм данных из CSV, а затем выбирается столбец College и fillna() метод fillna() .
# импорт модуля панд
import pandas as pd
# создание фрейма данных из CSV-файла
nba = pd.read_csv( «nba.csv» )
# замена значений в колледже на Нет колледжа
nba[ «College» ].fillna( «No College» , inplace = True )

Пример № 2: Использование метода Parameter
В следующем примере метод устанавливается как ffill, и, следовательно, значение в том же столбце заменяет нулевое значение. В этом случае штат Джорджия заменил нулевое значение в столбце колледжа строк 4 и 5.
Точно так же можно использовать методы bfill, backfill и pad.
# импорт модуля панд
import pandas as pd
# создание фрейма данных из CSV-файла
nba = pd.read_csv( «nba.csv» )
# замена значений в колледже на Нет колледжа
nba[ «College» ].fillna( method = ‘ffill’ , inplace = True )

Пример № 3: Использование лимита
В этом примере в методе fillna () устанавливается предел 1, чтобы проверить, прекращает ли функция замену после одной успешной замены значения NaN или нет.
# импорт модуля панд
import pandas as pd
# создание фрейма данных из CSV-файла
nba = pd.read_csv( «nba.csv» )
# замена значений в колледже на Нет колледжа
nba[ «College» ].fillna( method = ‘ffill’ , limit = 1 , inplace = True )
Выход:
Как показано в выходных данных, столбец колледжа 4-й строки был заменен, а 5-й столбец — нет, поскольку был установлен предел 1.
Источник



