- Телеметрия Windows 10. Как настроить сбор диагностических данных
- Содержание
- Параметры телеметрии в Windows 10
- Уровни телеметрии
- Безопасность
- Базовая настройка
- Расширенные данные
- Полные данные
- Настройка телеметрии через редактор локальной групповой политики
- Настройка телеметрии через системный реестр
- Часто задаваемые вопросы
- Автоматизация процесса контроля качества данных корпоративного хранилища
Телеметрия Windows 10. Как настроить сбор диагностических данных
Windows 10 – это не первая операционная система Microsoft, которая собирает диагностические данные. Однако, именно в Windows 10 Microsoft серьезно изменила структуру собираемых данных, а также предоставила пользователям возможность контролировать параметры телеметрии.
Концепция “Windows как служба” сыграла важную роль в изменении политики телеметрии. Компания решила отказаться от схемы выхода новой версии системы раз в три года и перешла на модель выхода двух функциональных обновлений для системы в год.
Телеметрия или диагностические данные играют важную роль в развитии операционной системы, потому что Microsoft использует эти данные для анализа и улучшения Windows.
Во всех редакциях Windows 10, за исключением Enterprise, сбор диагностических данных включен по умолчанию. На самом деле большинство версий Windows 10 поставляются без возможности полностью отключить сбор телеметрической информации.
Хотя вы можете ограничить сбор данных, перейдя на объем сбора данных “Основные”, полностью заблокировать функцию телеметрии не получится.
Содержание
Параметры телеметрии в Windows 10
Windows 10 поддерживает 4 различных параметра сбора телеметрических данных, но в приложении Параметры доступно только два из них – Основные и Полные. Два оставшихся диагностических уровня “Безопасность” и “Расширенные данные” можно включить только с помощью редактора локальной групповой политики или редактора системного реестра.
Порядок уровней сбора данных в зависимости от объема следующий: Полные > Расширенные данные > Основные > Безопасность.
Примечание: уровень “Расширенные данные” не отображается, ни на этапе первоначальной настройки системы, ни в приложении Параметры. Скорее всего, Microsoft в ближайшее время от него полностью откажется.
Приложение Параметры предоставляет такой же контроль над параметры телеметрии, который вы получаете при первоначальной настройке операционной системы.
- Используйте сочетание клавиша Windows + I для запуска приложения Параметры.
- Перейдите в раздел Конфиденциальность > Диагностика и отзывы > Диагностические данные .
По умолчанию используется объем передачи данных “Полные”. На данном уровне Windows 10 собирает большой объем данных и регулярно отправляет их на серверы Microsoft.
Вы можете переключиться на уровень “Основные” в приложении Параметры, чтобы ограничить сбор данных. Объем данных “Основные” – самый минимальный уровень сбора, доступный в потребительских версиях Windows 10.
Если вы являетесь участником программы предварительного тестирования Windows 10 Insider Preview, то на вашем устройстве на постоянной основе будет настроен уровень “Полные”.
Примечание: Компания Microsoft выпустила новую сборку Windows 10 Insider Preview Build 19577, в которой представлены новые названия для параметров диагностических данных.
Совет: Microsoft впервые сообщила о том, какие данные собираются на этом уровне в середине 2017 года. Первое обновление функций Windows 10 в 2018 представит инструмент для просмотра собираемых данных, и, кроме того, пользователь сможет удалить собранную информацию.
Уровни телеметрии
Итак, доступны следующие уровни телеметрии:
Безопасность
Значение 0 (Безопасность) будет отправлять минимальное количество данных в корпорацию Майкрософт для безопасности Windows. Компоненты системы безопасности Windows, такие как средство удаления вредоносных программ (MSRT) и Защитник Windows, могут отправлять данные в корпорацию Майкрософт на этом уровне, если они включены.
Базовая настройка
Значение 1 (Основные) отправляет те же данные, что и значение 0, а также крайне ограниченный объем данных диагностики, например, базовые сведения об устройстве, данные о качестве и сведения о совместимости приложений. Обратите внимание, что значения 0 или 1 отрицательно скажутся на некоторых функциональных возможностях устройства.
Расширенные данные
Значение 2 (Улучшенные) отправляет те же данные, что и значение 1, а также дополнительные данные, например, об использовании Windows, Windows Server, System Center и приложений, их производительности и расширенные данные по безопасности.
Полные данные
Значение 3 (Полные) отправляет те же данные, что и значение 2, а также дополнительные данные диагностики, используемые для диагностики и устранения неполадок в устройствах. Такими данными могут быть файлы и содержимое, которые могли стать причиной проблемы в устройстве.
Настройка телеметрии через редактор локальной групповой политики
В редакторе локальной групповой политике показываются все четыре уровня сбора телеметрии, но только три из них доступны для потребительских устройств.
Чтобы запустить редактор локальной групповой политики, проделайте следующие шаги
Примечание: недоступно в Windows 10 Домашняя
- Нажмите клавишу Windows , чтобы открыть меню Пуск.
- Введите gpedit.msc и нажмите Enter.
Перейдите по следующему пути:
Дважды кликните по политике Разрешить телеметрию (или Разрешить сбор диагностических данных), чтобы отобразить открыть окно управления политикой.
По умолчанию политика не настроена, а это значит, что используется значение, заданное во время предварительной настройки или в приложении Параметры. Значение “Отключено” имеет аналогичный эффект – это не означает, что сбор телеметрии полностью отключен на устройстве.
Потребители и небольшие компании могут выбрать объем данных диагностики “Базовая настройка”, “Расширенные данные” и “Полные данные”. Хотя вы можете выбрать уровень “Безопасность” делать это не рекомендуется, потому что в потребительских версиях будет выполнено автоматическое переключение на уровень “Базовая настройка” и могут возникнуть проблемы с доставкой обновлений для системы.
Настройка телеметрии через системный реестр
Вы можете настроить объем собираемых диагностических данных в системном реестре. Эти действия принесут такой же результат, как и использование редактора локальной групповой политики.
- Нажмите клавишу Windows , чтобы открыть меню Пуск.
- Введите regedit.exe и нажмите Enter.
- Подтвердите запрос службы контроля учетных записей.
Чтобы настроить телеметрию перейдите по пути:
Измените значение параметра Dword с именем AllowTelemetry на одно из значений:
- 0 – Безопасность (только Enterprise)
- 1 – Базовая настройка
- 2 – Расширенные данные
- 3 – Полные данные
Примечание:
Если раздел DataCollection не существует, кликните правой кнопкой мыши в древовидном меню и выберите Создать > Раздел .
Если параметр Dword для AllowTelemetry не существует, кликните правой кнопкой мыши по разделу DataCollection и выберите Создать > Параметр DWORD (32 бита) для его создания.
Часто задаваемые вопросы
Что такое телеметрия в Windows 10?
Телеметрия или диагностические данные – это данные, которые Windows 10 автоматически собирает для отправки на серверы Microsoft. Microsoft заявляет, что данные обезличены и помогают компании разрабатывать Windows 10.
Как отключить сбор данных Windows 10?
Вы не можете сделать это, используя встроенные функции операционной системы. Вы только можете изменить уровень уровень сбора телеметрии с “Полные” на “Основные”, чтобы ограничить объем передаваемых Microsoft данных.
Неужели нет другого способа?
Существует способ, но он может повлиять на функциональность других компонентов операционной системы. Вам необходимо заблокировать серверы Microsoft, чтобы предотвратить соединение с этими серверами. Используйте скрипт Debloat Windows 10, который выполняет блокировку серверов, но сначала создайте резервную копию системы.
В чем разница между диагностическими данными и другими параметрами конфиденциальности Windows 10?
Телеметрия относится к автоматическому сбору диагностических данных. Остальные настройки конфиденциальности в основном определяют разрешения приложений. Эти настройки не считаются телеметрией, но они по-прежнему связаны с конфиденциальностью.
Источник
Автоматизация процесса контроля качества данных корпоративного хранилища
В «Ростелекоме», как и в любой крупной компании, имеется корпоративное хранилище данных (ЦХД). Наше ЦХД постоянно разрастается и расширяется, мы строим на нем полезные витрины, отчеты и кубы данных. В какой-то момент мы столкнулись с тем, что некачественные данные мешают нам при построении витрин, получаемые агрегаты не сходятся с агрегатами систем источников и вызывают непонимание бизнеса. Например, данные с Null значениями в внешних ключах (foreign key) не соединяются с данными других таблиц.
Краткая схема ЦХД:

Мы понимали, что для обеспечения уверенности в качестве данных нам нужен регулярный процесс сверок. Конечно, автоматизированный и позволяющий каждому из технологических уровней быть уверенным в качестве данных и их сходимости, как по вертикали, так и по горизонтали. В итоге мы параллельно рассмотрели три готовые платформы для управления сверками от различных вендоров и написали свою собственную. Делимся опытом в этом посте.
Минусы готовых платформ всем известны: цена, ограниченная гибкость, отсутствие возможности дописать и исправить функциональность. Плюсы — закрываются также части mdm (золотые данные и прочее), обучение и поддержка. Оценив это, мы быстро забыли про покупку и сконцентрировались на разработке своего решения.
Ядро нашей системы написано на Python, а база данных метаданных хранения, журнализации и хранения результатов — на Oracle. Библиотек для Python написано много, мы используем необходимый минимум для коннектов Hive(pyhive), GreenPlum(pgdb), Oracle(cx_Oracle). Подключение источника другого типа также не должно составить проблем.
Полученные наборы данных (result set) мы складываем в результирующие таблицы Oracle, на ходу оценивая статус прохождения сверки (SUCCESS/ERROR). На результирующие таблицы настроен APEX в котором построена визуализация результатов, удобная как сопровождению, так и руководству.
Для запуска проверок в Хранилище используется оркестратор Informatica, который загружает данные. При получении статуса успешности загрузки эти данные автоматически начинают сверяться. Применение параметризации запросов и метаданных ЦХД позволяет использовать шаблоны запросов-сверок для наборов таблиц.
Теперь о реализованных на данной платформе сверках.
Начинали мы с технических сверок, которые сравнивают количество данных на входе и слоях ЦХД с наложением определенных фильтров. Берем пришедший на вход в ЦХД ctl-файл с данными, считываем из него количество записей и сравниваем с таблицей на Stage ODL и/или Stage ODS (1, 2, 3 на схеме). Критерий сверки определен в равенстве количества записей (count). Если количество сходится, то результат SUCCESS, нет — ERROR и ручной разбор ошибки.
Эта цепочка технических сверок по сравнению количества записей тянется до слоя ADS (8 на схеме). Меняются фильтры между слоями, которые зависят от типа загрузки — DIM (справочник), HDIM (исторический справочник), FACT (фактовые таблицы начислений) и т.д., — а также от версионности SCD и слоя. Чем ближе к витринному слою, тем более сложные алгоритмы фильтрации мы используем.
На входных данных также сделана техническая сверка на Python, обнаруживающая дубли в ключевых полях. У нас в GreenPlum ключевые поля (PK) не защищены от дублей системными средствами БД. Так что мы написали скрипт Python, который считывает из метаданных PK поля загруженной таблицы и генерирует SQL-скрипт, проверяющий отсутствие дублей по ним. Гибкость подхода позволяет нам использовать PK, состоящий из одного или нескольких полей, что крайне удобно. Такая сверка тянется до STG ADS слоя.
Пример python-кода сверки уникальности. Вызов, передача параметров коннекта и укладывание результатов в результирующую таблицу осуществляется управляющим модулем на Python.
Сверка на отсутствие NULL значений построена аналогично предыдущей и тоже на Python. Считываем из метаданных загрузки поля, которые не могут иметь пустых (NULL) значений и проверяем их наполненность. Сверка используется до слоя DDS (6 на первой схеме).
На входе в хранилище также реализован тренд-анализ поступающих на вход пакетов данных. Количество пришедших данных при поступлении нового пакета заносится в таблицу истории. При существенном изменении количества данных ответственный за таблицу и СИ (систем-источник) получает уведомление на почту (в планах), видит в APEX ошибку еще до попадания сомнительного пакета данных в Хранилище и выясняет с СИ причину этого.
Между STG (STAGE)_ODS и ODS (слоем оперативных данных) (3 и 4 на схеме) появляются технические поля удаления (индикатор удаления = deleted_ind), корректность заполнения которых мы тоже проверяем средствами SQL запросов. Отсутствующие на входе данные должны быть помечены удаленными в ODS.
Результатом работы скрипта сверки ожидаем увидеть нулевое количество ошибок. В представленном примере сверки параметры
— передаются через управляющий блок Python, а параметры типа
заполняются из метаданных таблицы, само имя таблицы
из параметров запуска.
Ниже приведена параметризованная сверка. Пример SQL кода сверки между STG_ODS и ODS для типа HDIM:
Пример SQL кода сверки между STG_ODS и ODS для типа HDIM с подставленными параметрами:
Начиная с ODS, в справочниках ведется история, следовательно, ее надо проверить на отсутствие пересечений и разрывов. Это сделано через подсчет количества некорректных значений в истории и запись полученного количества ошибок в результирующую таблицу. При наличии в таблице ошибок ведения истории их придется искать уже вручную. Сверка зависит от типа загрузки — HDIM (справочник с ведением истории) в первую очередь. Сверки корректности истории ведем для справочников до слоя ADS.
На слое DDS (6 на первой схеме) разные СИ (системы-источники) соединяются в одну таблицу, появляются HUB таблицы генерации суррогатных ключей для связки данных из разных систем источников. Их мы проверяем на уникальность python-проверкой, аналогичной stage-слою.
На слое DDS необходимо проверить, что после объединения с HUB-таблицей в ключевых полях не появилось значений типа 0, -1, -2, означающих некорректное объединение таблиц, отсутствие данных. Они могли появиться при отсутствии в HUB-таблице нужных данных. И это ошибка для ручного разбора.
Самые сложные сверки у данных витринного слоя ADS (8 на первой схеме). Для полной уверенности в сходимости полученного результата здесь развернута верификация с системой-источником по агрегации суммы начислений. С одной стороны, есть класс показателей, в которые входят агрегированные начисления. Мы собираем их за месяц из витрины ЦХД. С другой стороны, берем агрегаты этих же начислений из системы-источника. Допустимо расхождение не более 1% или определенного и согласованного абсолютного значения. Полученные сверкой наборы данных (result sets) помещаем в специально созданные под получаемые наборы данных, результирующие таблицы Oracle. Сравнение данных делаем в представлении Oracle. Визуализацию полученных результатов в APEX. Наличие целого набора данных (result set) позволяет нам, при наличии ошибок проваливаться глубже и анализировать детальные данные результата, находить конкретную статью по которой произошло расхождение, искать его причины.
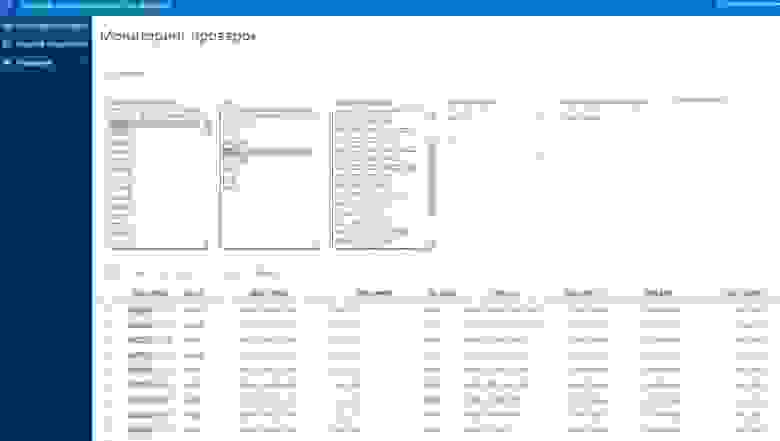
Представление результатов сверок для пользователей в APEX
На данный момент у нас получилось работоспособное и активно используемое приложение для сверок данных. Конечно же у нас в планах дальнейшее развитие как количества и качества сверок, так и развития самой платформы. Собственная разработка позволяет нам изменять и дорабатывать функционал достаточно быстро.
Статья подготовлена командой управления данными «Ростелекома»
Источник



