- MS SQL Server: пошаговая настройка репликации
- SQL Server: основы технологии репликации
- Настройка распространителя в SQL Server
- Настройка издателя репликации в SQL Server
- Настройка подписчика репликации в SQL
- Мониторинг и управление репликацией в SQL Server
- Репликация баз данных MySQL. Введение
- Что такое репликация, и зачем она нужна
- Как MySQL реплицирует данные
- Виды репликации
- Пример построения простой репликации в MySQL
- Заключение
MS SQL Server: пошаговая настройка репликации
В этой статье мы рассмотрим, как настроить самый распространений тип репликации в SQL Server – транзакционную репликацию. Этот тип репликации SQL Server используется для копирования данных в режиме реального времени, то есть данные на подписчиках появляются практически сразу (с учетом времени которое тратится на копирование данных по сети).
Репликация транзакций проста в настройке и доступна во всех версиях SQL Server. Данный тип репликации используется для двух целей:
- Репликация данных между несколькими серверами для read доступа (например, для разгрузки серверов OLTP типа);
- Как решение для избыточности данных отдельных объектов.
Хотя у SQL Server есть много решений для балансировки нагрузки select запросов и средств обеспечения отказоустойчивости, транзакционная репликация это самый простой и быстрый способ, так как вы можете реплицировать отдельные объекты. Так же этот вид репликации полностью доступен в Standard лицензии SQL Server ( в отличии от групп доступности Always On, которые полноценно доступны только в Enterprise).
Преимущество репликации перед Always ON и зеркалированием баз данных в том, что с помощью репликации вы можете скопировать отдельные объекты (отдельные таблицы/представления), а не базу данных целиком.
Единственный минус транзакционной репликации —она не может работать в синхронном режиме – то есть, дожидаться завершения транзакции на подписчиках. Поэтому в случае форс-мажорного выключения любого участника репликации, данные могут быть потеряны или может произойти рассинхронизация между издателем и подписчиками.
SQL Server: основы технологии репликации
В любом типе репликации SQL Server есть 3 типа серверов:
- Publisher (издатель) – основной экземпляр-источник, который публикует статьи;
- Distributor (распространитель) – экземпляр который распространяет статьи на сервера-подписчики. Этот тип экземпляра не хранит у себя данные издателя на постоянной основе, а распространяет их подписчикам;
Роли могу пересекаться между собой. Например, один экземпляр может быть и издателем, и подписчиком (но не самого себя).
Работа репликации транзакций осуществляется через внутренние агенты SQL Server’а:
- Агент чтения журналов;
- Агент моментальных снимков;
- Агент распространения.
При появлении транзакций в объектах, участвующих в репликации, на издателе, агент чтения журналов копирует эти транзакции на экземпляр-распространитель, затем агент распространитель копирует данные на подписчиков. Агент моментальных снимков участвует только тогда, когда нужно скопировать новый моментальный снимок (обычно это происходит при инициализации и реинициализации репликации).
Транзакции доставляются на подписчиков в той последовательности, в которой они были отправлены на издателя. Если транзакций слишком много, образуется очередь.
Транзакционная репликация работает асинхронно, так же как и асинхронные режимы Always On и зеркалирования баз данных. То есть, данные, которые были записаны на издатель, будут отправлены на подписчики без гарантии доставки в случае сбоя во время передачи данных. Это нужно учитывать, если вы собираетесь использовать транзакционную репликацию для избыточности и высокой доступности данных в SQL Server.
Схема связи агентов между собой из официальной документации:
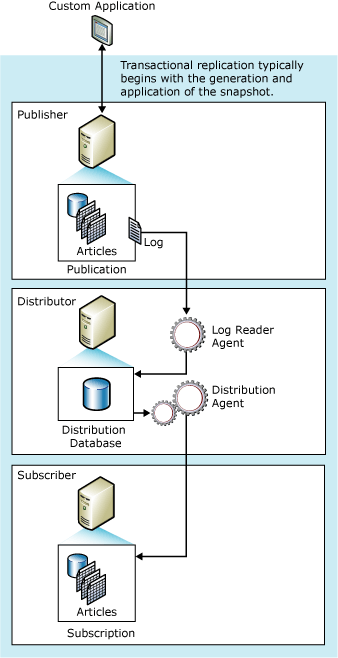
Рассмотрим, как настроить репликацию в SQL Server на следующем тестовом стенде:
- 2 виртуальные машины с Windows Server 2019 в одной сети;
- 2 установленных экземпляра SQL Server 2019.
- testnode1\node1 – издатель (Publisher);
- testnode2\node2 – подписчик (Subscriber);
- testnode2\node2 – распространитель (Distributor).
В этом примере мы будем реплицировать одну таблицу с testnode1\node1 на testnode\node2. В роли распространителя будет выступать testnode2\node2.
Настройка распространителя в SQL Server
Для начала нужно настроить экземпляр распространителя. В разделе Replication, в контекстном меню нажмите Configure Distribution…
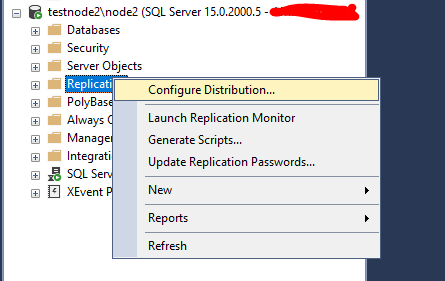
Так как мы хотим использовать этот экземпляр в качестве распространителя, выбираем первый пункт (testnove2 will act as its own Distributor; SQL Server will create a distribution databasse and log).
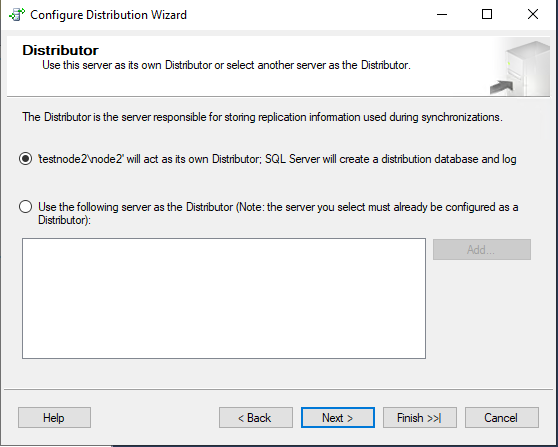
Указываем директорию для моментальных снимков. Я оставлю стандартный путь. 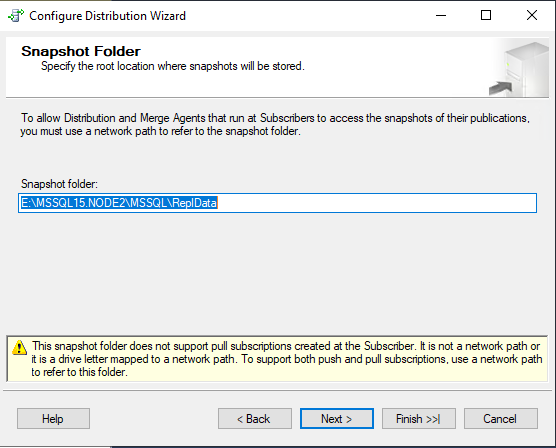
Указываем директорию для базы данных Distribution. Если есть такая возможность, то лучше разместить файлы базы данных distribution на отдельном массиве дисков. Особенно это важно, если планируется большой объём реплицируемых данных. 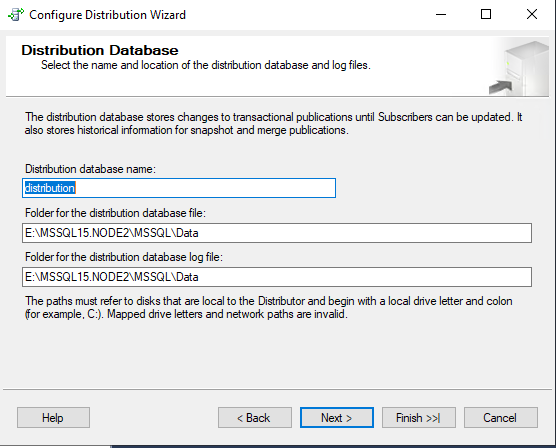
На этом шаге можно указать экземпляры, которые смогут использовать данный сервер как распространитель. Я сразу добавлю testnode1\node1. Это можно сделать и позже, после начальной конфигурации.
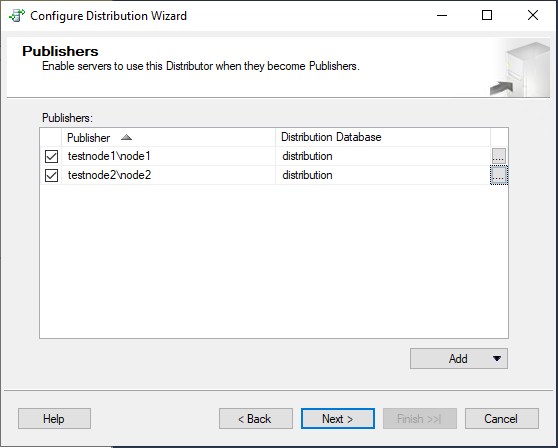
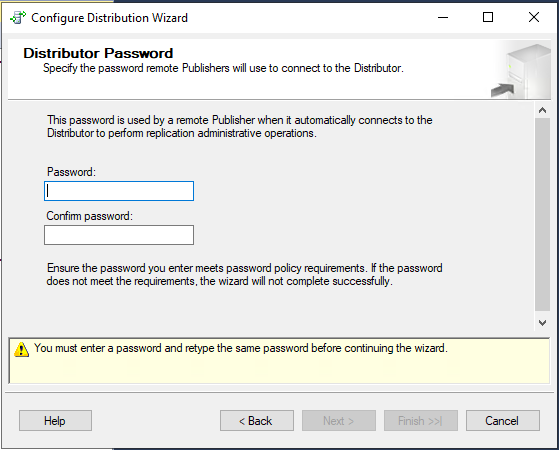
Укажите пароль для связи с экземплярами, которые будут связываться с распространителем.
После этого можно жать Finish. На этом настройка распространителя завершена.
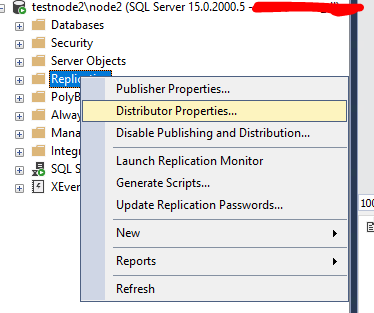
Если вы хотите изменить пароль распространителя или разрешить другим издателям использовать этот распространитель, то можно это сделать через Distributor Properties…
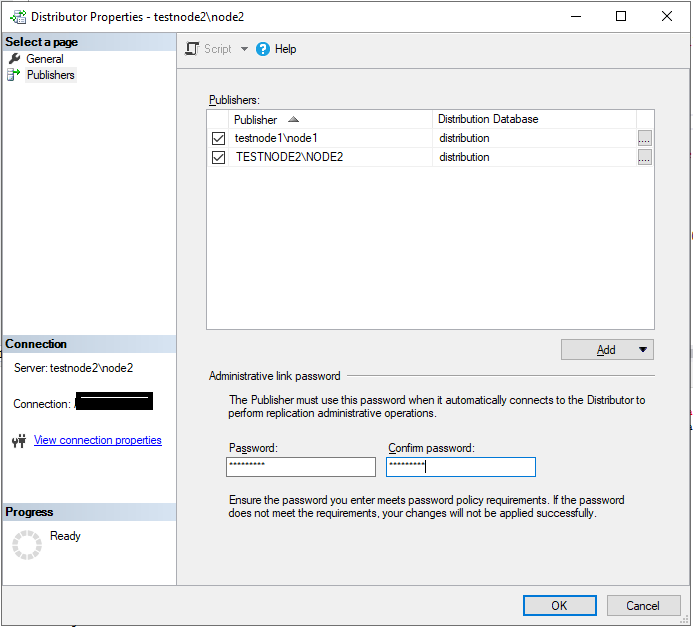
Настройка издателя репликации в SQL Server
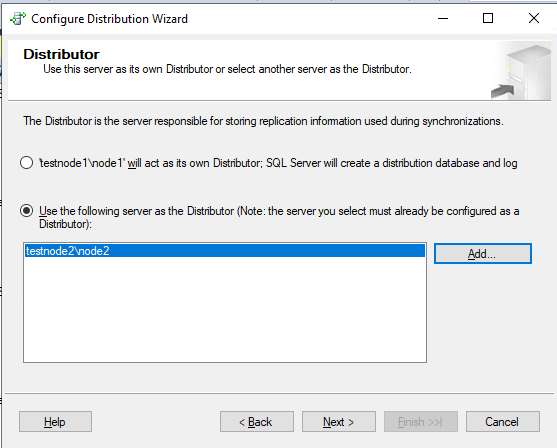
Теперь переходим к настройкам издателя репликации. Запустите тот же мастер Configure Distributuin.
Выберите второй пункт, указываем сервер распространитель – testnode2\node2
После этого введите пароль, который вы указывали при настройке распространителя и нажмите Finish.
Теперь можно создать новую публикацию: Replication -> Local Publication -> New Publication.
Укажите базу данных, которая будет участвовать в репликации.
Выберите тип репликации. Доступны:
- Snapshot publication;
- Transactional publication (выберите этот тип репликации);
- Peer-to-Peer publication;
- Merge publication.
![]()
Выберите таблицы, которые нужно реплицировать. С помощью транзакционной репликации так же можно реплицировать пользовательские процедуры, функции и представления. Реплицируемые объекты называются Articles (Статьи).
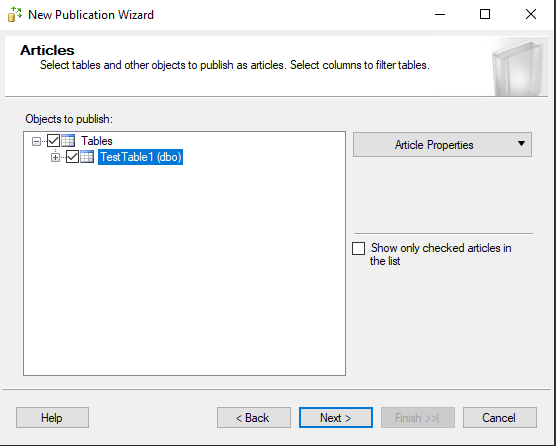
На следующем шаге можете указать фильтр для публикации.
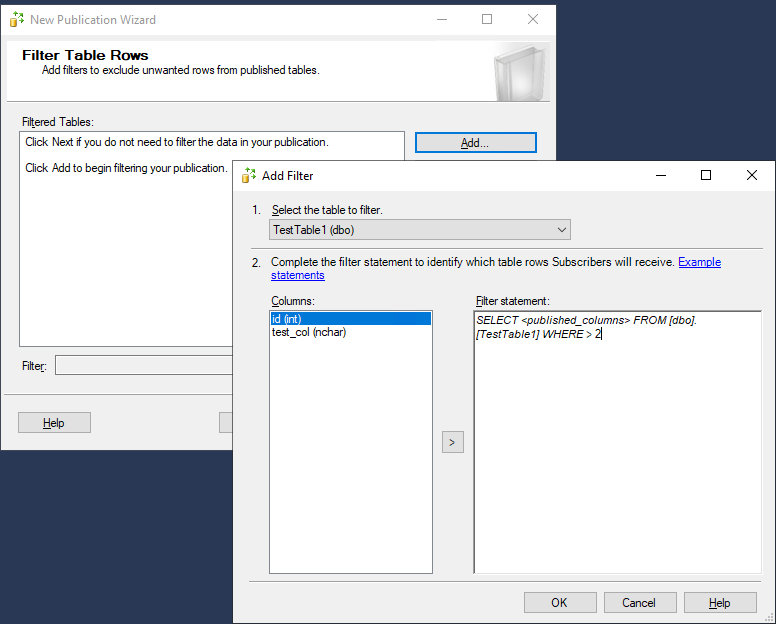
Чтобы мастер сразу создал моментальный снимок, выберите опцию “Create a snapshot immediately and keep the snapshot available to initialize subscriptions”.
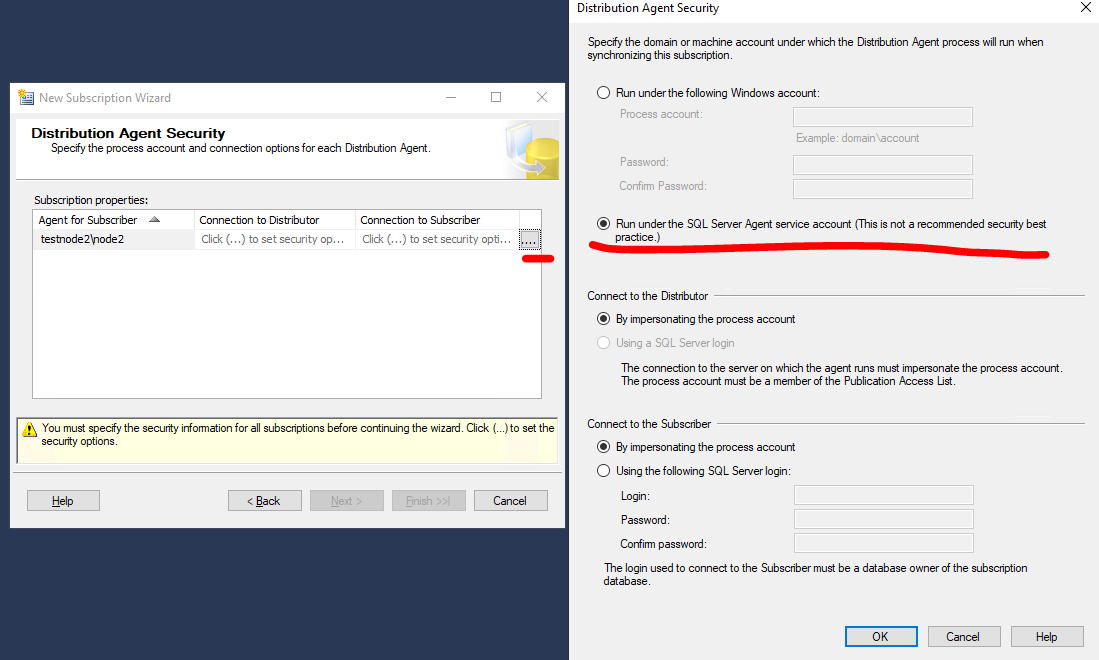
Укажите аккаунты, из-под которых будут выполняться агенты. Нажмите Security Settings и выберите “Run under SQL Server Agent service account”. 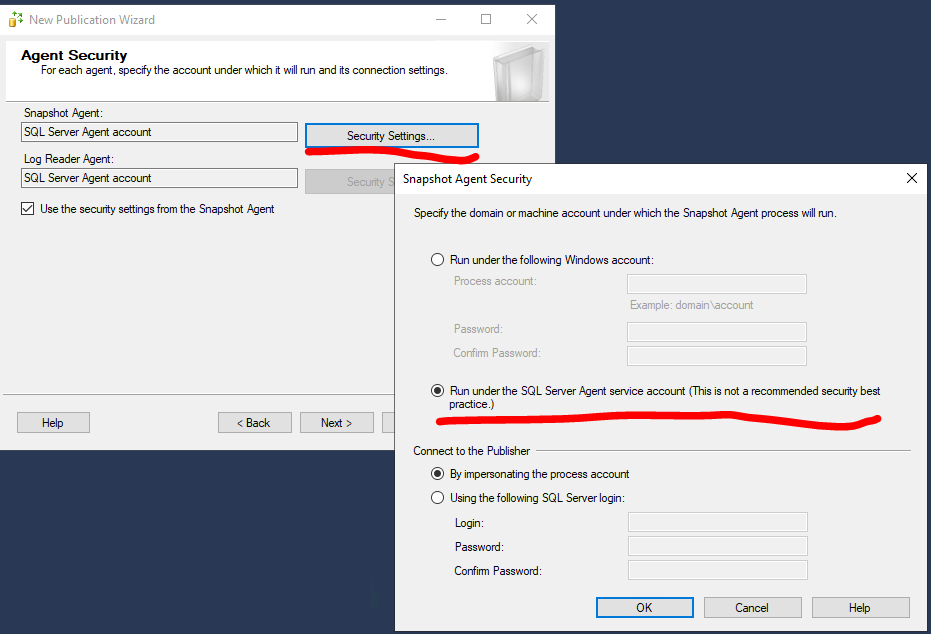
В имени публикации я указываю названия сервера-подписчика. Так легче ориентироваться если публикаций на другие сервера будет много.
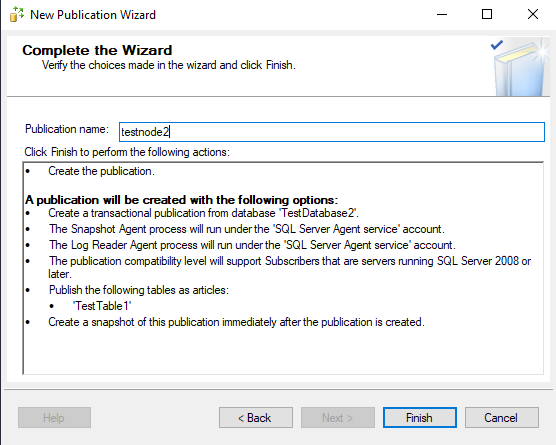
Настройка подписчика репликации в SQL
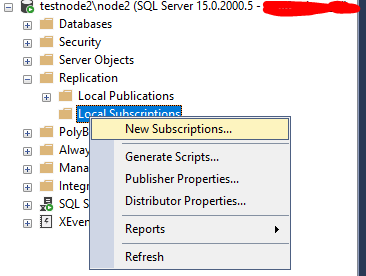
На testnode2\node2 в разделе Replication -> Local Subscriptions создайте новую подписку.
 Local Subscriptions в sql server» width=»339″ height=»256″ srcset=»https://winitpro.ru/wp-content/uploads/2020/02/sozdat-podpisku-replikacii-greater-local-subscriptions.png 366w, https://winitpro.ru/wp-content/uploads/2020/02/sozdat-podpisku-replikacii-greater-local-subscriptions-300×226.png 300w» sizes=»(max-width: 339px) 100vw, 339px»/>
Local Subscriptions в sql server» width=»339″ height=»256″ srcset=»https://winitpro.ru/wp-content/uploads/2020/02/sozdat-podpisku-replikacii-greater-local-subscriptions.png 366w, https://winitpro.ru/wp-content/uploads/2020/02/sozdat-podpisku-replikacii-greater-local-subscriptions-300×226.png 300w» sizes=»(max-width: 339px) 100vw, 339px»/>
Выберите издателя, базу данных и публикацию в ней.
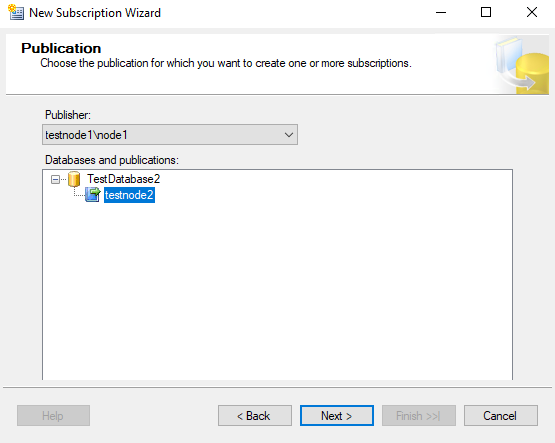
Выберите пункт “Run all agents at the Distributor”, чтобы агенты выполнялись на распространителе. В моём случае подписчик и распространитель совпадают, но обычно это разные сервера.
Если выбрать второй пункт (“Run each agent at its Subscriber”), то агенты будут выполняться на подписчике. Этот вариант предпочтителен, если распространитель у вас “формальный” и находится на одном сервере с издателем или подписчиком
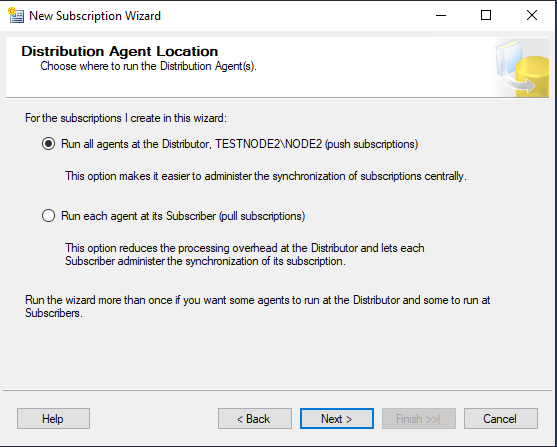
Укажите базу данных, в которую будут реплицироваться данные из Subscription Database.
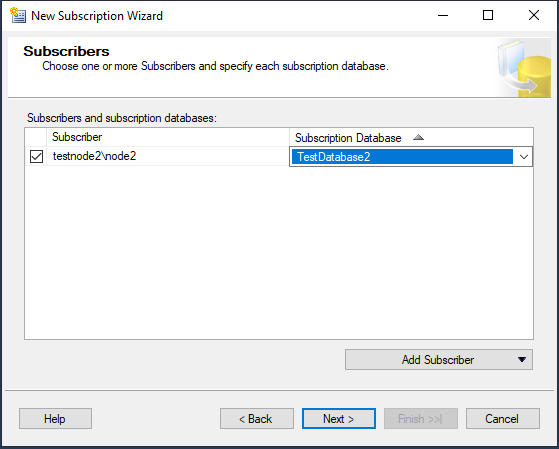
Снова укажите аккаунт, из-под которого будут выполняться агенты репликации.
Если вы хотите, чтобы данные реплицировались постоянно, выбирайте режим Agent Schedule -> Run continuously.
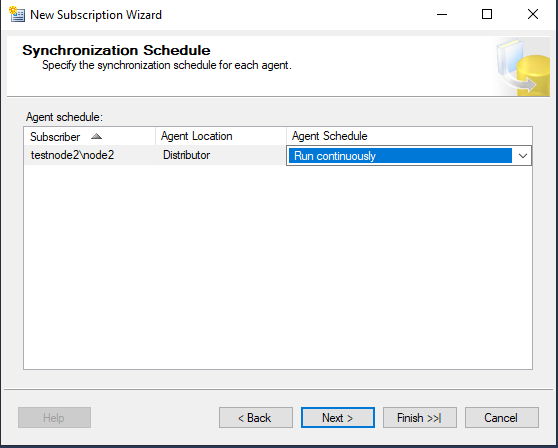
Включите опцию Initialize, чтобы инициализировать подписку после завершения работы мастера.
При включении параметра “Memory Optimized” таблицы на подписчике с этой публикации будут созданы как “In memory”. Если вы не планируете эти таблицы как таблицы для использования в оперативной памяти, то не отмечайте этот параметр. 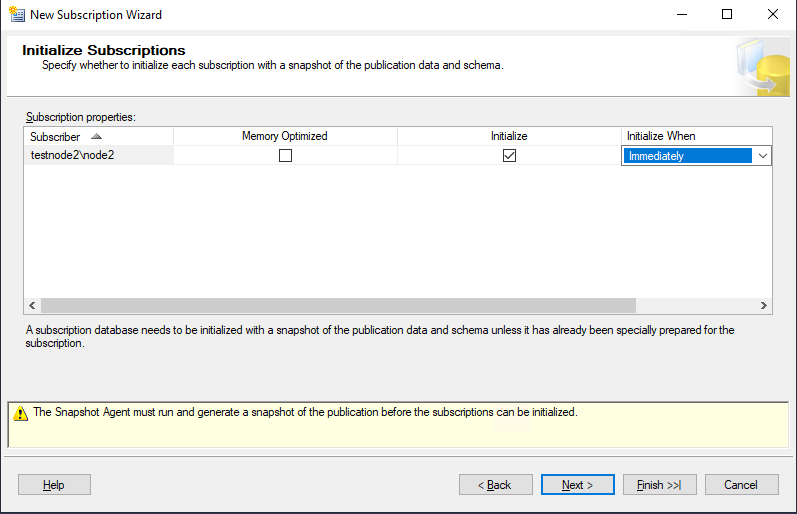
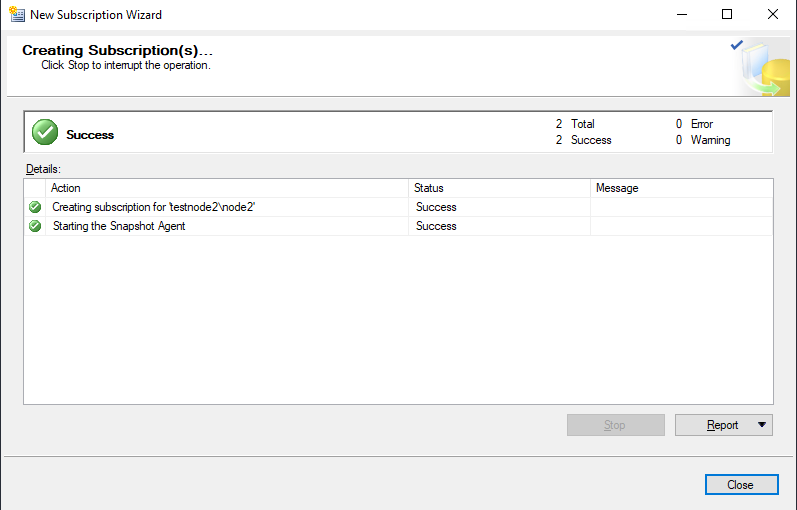 На этом настройка подписки завершена. Теперь необходимо проверить работоспособность публикации и корректность выполнения репликации таблицы.
На этом настройка подписки завершена. Теперь необходимо проверить работоспособность публикации и корректность выполнения репликации таблицы.
Мониторинг и управление репликацией в SQL Server
Практически всю настройку существующих публикаций можно провести через Replication Monitor.
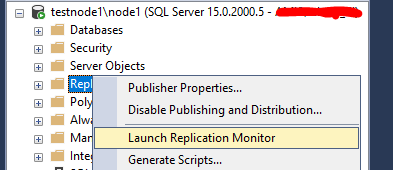
Добавьте издателей через распространителя (Add Publisher -> Specify a Distributor and Add its Publishers).
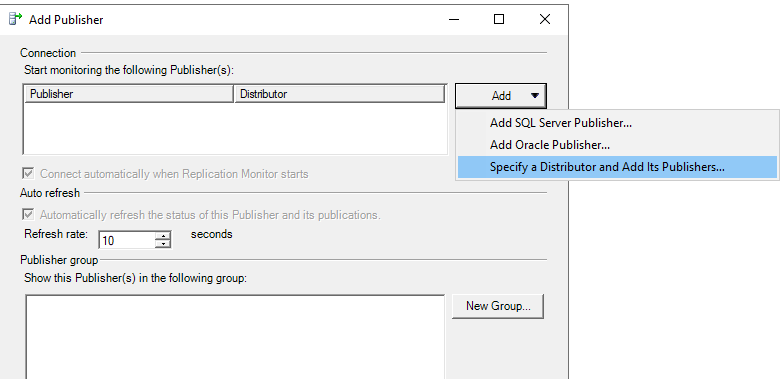
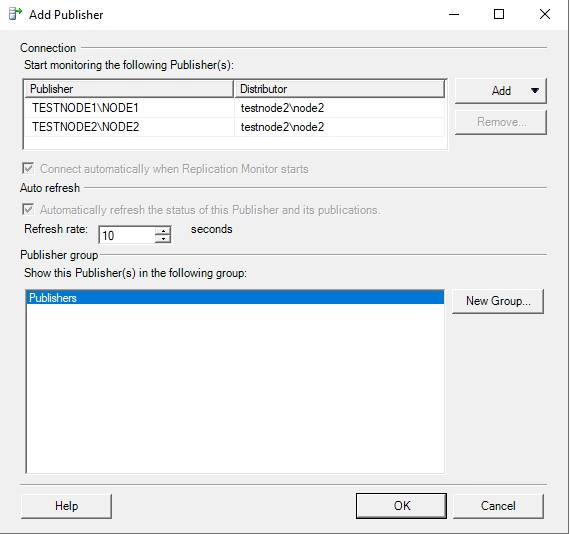
После того, как вы соединитесь с распространителем, у вас появится список издателей, которые работают с этим распространителем.
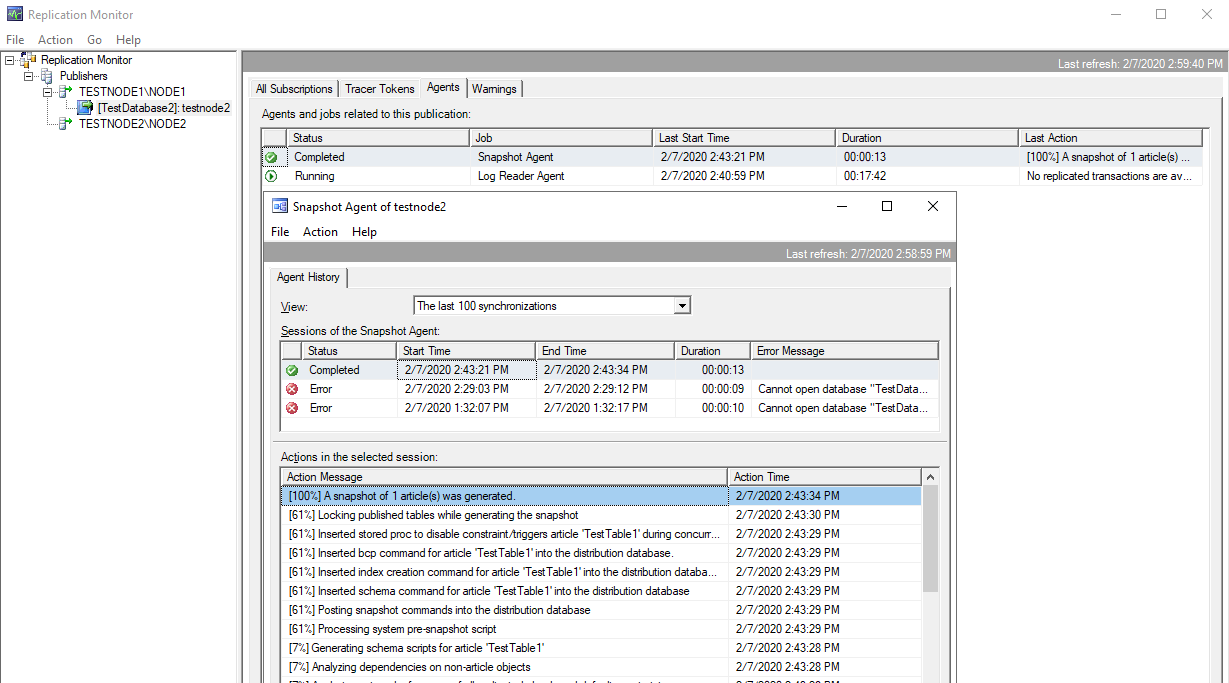
Убедимся, что агент моментальных снимков отработал и доставил снимок на распространителя. В моём случае сначала была ошибки о том, что аккаунту из-под которого работают агенты, не хватает прав на базе TestDatabase1. Для решения этой проблемы я добавил сервисному аккаунту (из-под которого работает SQL Server) роль db_owner в базе TestDatabase1 на обоих экземплярах.
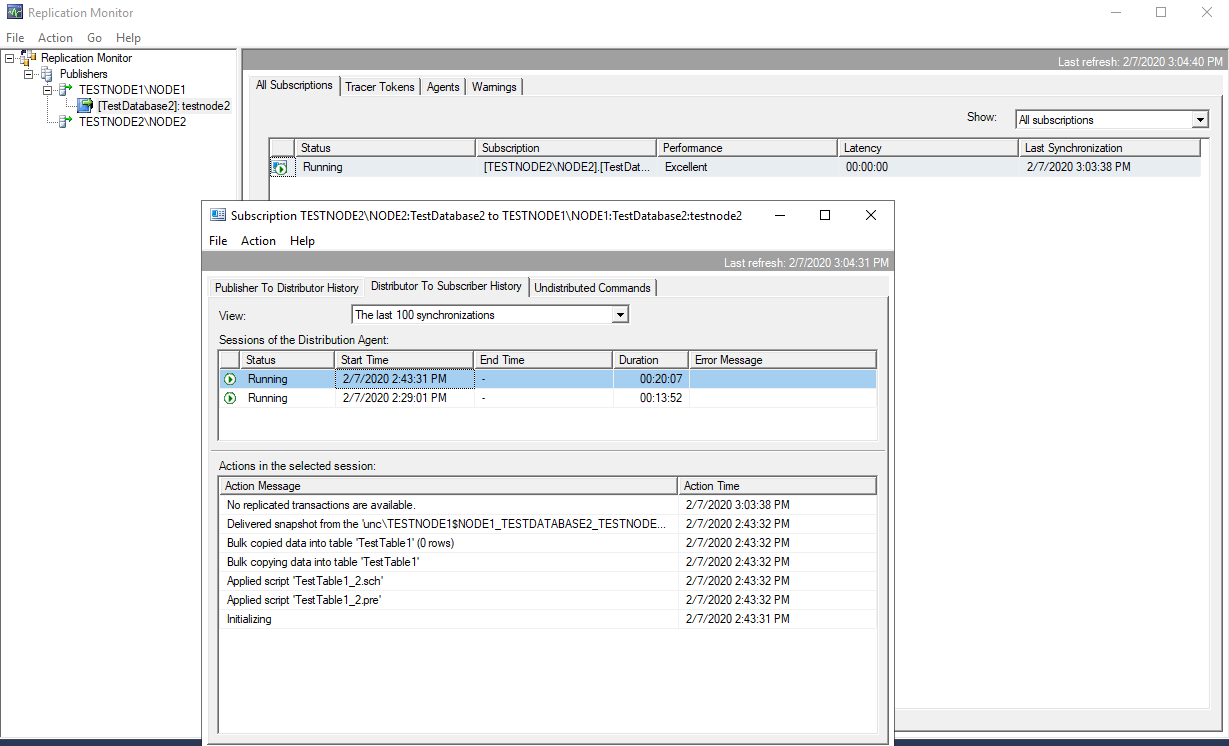
Так же убедимся, что распространитель доставил транзакции на подписчика.
В логах агентов ошибок нет, проверим что наша таблица действительно появилась в базе.
Для начала добавим новую запись в таблицу.
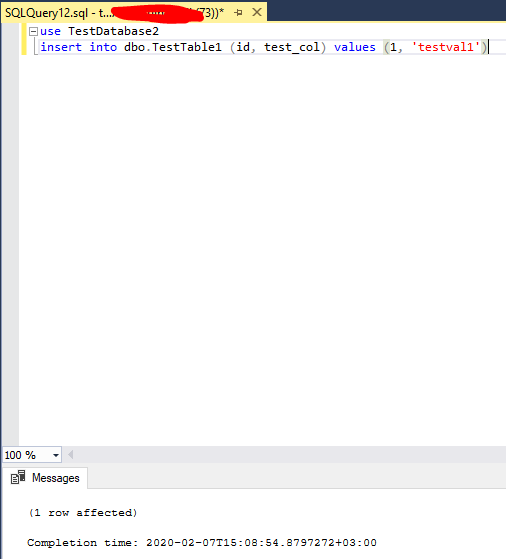
Проверяем, что эта запись реплицировалась на testnode2\node2.
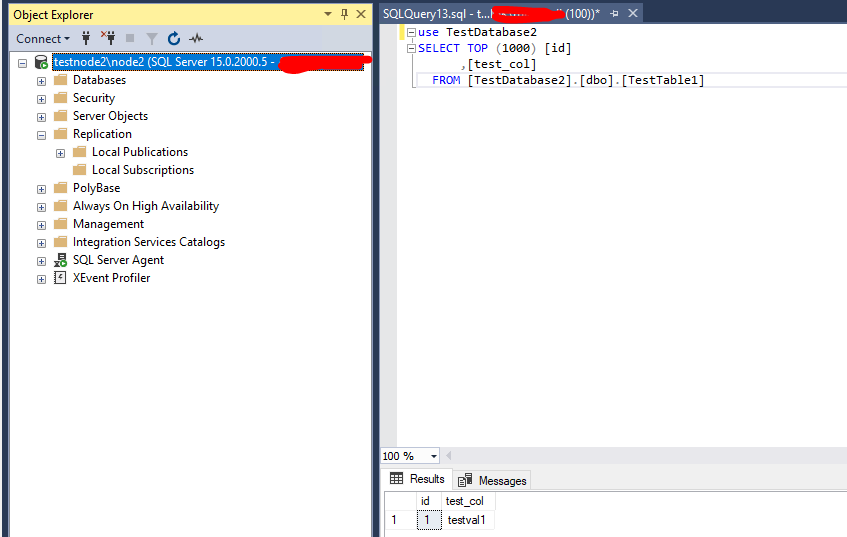
На этом базовая настройка репликации транзакций в SQL Server закончена.
Для диагностики проблем с репликацией в основном используется Replication Monitor, но можно использовать и дополнительные инструменты диагностики SQL Server.
Источник
Репликация баз данных MySQL. Введение
Редкая современная продакшн система обходится без репликации баз данных. Это мощный инструмент на пути к повышению производительности и отказоустойчивости системы, и современному разработчику очень важно иметь хотя бы общее представление о репликации. В данной статье я поделюсь базовыми знаниями о репликации, и покажу простой пример настройки репликации в MySQL с помощью Docker.

Что такое репликация, и зачем она нужна
Само по себе, понятие репликации означает процесс синхронизации нескольких копий объекта. В нашем случае, таким объектом является сервер БД, а наибольшую ценность представляют собой сами данные. Если мы имеем два и более серверов, и любым возможным способом поддерживаем синхронизированный набор данных на них — мы реализовали репликацию системы. Даже ручной вариант с mysqldump -> mysql load — это также репликация.
Стоит понимать, что сама по себе репликация данных не имеет ценности, и является лишь инструментом решения следующих задач:
- повышение производительности чтения данных. С помощью репликации мы сможем поддерживать несколько копий сервера, и распределять между ними нагрузку.
- повышение отказоустойчивости. Репликация позволяет избавиться от единственной точки отказа, которой является одиночный сервер БД. В случае аварии на основном сервере, есть возможность быстро переключить нагрузку на резервный.
- распространение данных. В современную эпоху глобализации ваше приложение может обслуживать пользователей со всего мира, и мы хотим, чтобы жители и Сиднея, и Хельсинки имели минимальную задержку доступа к нему.
- распределение нагрузки. В случае, если БД обслуживает запросы разных типов (быстрые и легкие, медленные и тяжелые), может иметь смысл развести эти запросы по разным серверам, для увеличения эффективности работы каждого типа.
- тестирование новых конфигураций. С помощью репликации есть возможность проведения тестирования новых версий сервера БД, изменения параметров конфигурации, и даже изменения типов хранилища данных.
- резервное копирование. С помощью репликации есть возможность делать механизмы резервного копирования более гибкими и вносить меньше негативных эффектов в работающую систему.
Как MySQL реплицирует данные
Процесс репликации подразумевает собой распространение изменений данных с главного сервера (обычно он называется как мастер, master), на один или более подчиненных серверов (слейв, slave). Существуют и более сложные конфигурации, в частности с несколькими мастер-серверами, но для каждого изменения на конкретном мастер-сервере остальные мастера условно становятся слейвами, и потребляют эти изменения.
В общем виде, репликация в MySQL состоит из трех шагов:
- Мастер-сервер записывает изменения данных в журнал. Этот журнал называется двоичным журналом (binary log), а изменения — событиями двоичного журнала.
- Слейв копирует изменения двоичного журнала в свой, который называется журналом ретрансляции (relay log).
- Слейв воспроизводит изменения из журнала ретрансляции, применяя их к собственным данным.
Виды репликации
Существует два принципиально разных подхода к репликации: покомандная и построчная. В случае покомандной репликации, в журнал мастера протоколируются запросы изменения данных (INSERT, UPDATE, DELETE), а слейвы в точности воспроизводят те же команды у себя. При построчной же репликации в журнале окажутся непосредственно изменения строк в таблицах, и эти же фактические изменения применятся затем на слейве.
Как нет серебряной пули, так и каждый из этих методов имеет свои преимущества и недостатки. Покомандная репликация проще в реализации и понимании, снижает нагрузку на мастер и на сеть. Но тем не менее, покомандная репликация может приводить к непредсказуемым эффектам, при использовании недетерминированных функций, таких как NOW(), RAND(), и т.д. Могут быть также проблемы, вызванные рассинхронизацией данных между мастером и слейвом. Построчная же репликация приводит к более прогнозируемым результатам, так как фиксируются и воспроизводятся фактические изменения данных. Тем не менее этот метод может значительно увеличивать нагрузку на мастер-сервер, которому приходится фиксировать каждое изменение в журнале, и на сеть, через которую эти изменения распространяются.
В MySQL поддерживаются оба способа репликации, а дефолтный (можно сказать, что и рекомендуемый) изменялся в зависимости от версии. В современных версиях, например MySQL 8, по умолчанию используется построчная репликация.
Второй принцип разделения подходов к репликации — количество мастер-серверов. Наличие одного мастер сервера подразумевает, что только он принимает изменения данных, и является неким эталоном, с которого уже распространяются изменения на множество слейвов. В случае же с мастер-мастер репликацией мы получаем как и некоторый профит, так и проблемы. Один из плюсов, например, то, что мы можем давать удаленным клиентам из тех же Сиднея и Хельсинки одинаково быструю возможность записывать свои изменения в базу. Из этого исходит и главный недостаток, если оба клиента одновременно изменили одни и те же данные, чьи изменения считать окончательными, чью транзакцию коммитить, а чью откатывать.
Также, стоит отметить, что наличие мастер-мастер репликации в общем случае не может увеличить производительность записи данных в системе. Представим, что наш единственный мастер может обрабатывать до 1000 запросов в единицу времени. Добавив к нему реплицируемый второй мастер, мы не сможем обрабатывать по 1000 запросов на каждом из них, так как кроме обработки “своих” запросов, им придется применять изменения, сделанные на втором мастере. Что в случае покомандной репликации сделает суммарно возможную нагрузку на оба не больше, чем на самый слабый из них, а с построчной репликацией эффект не совсем предсказуемый, может быть как положительный, так и отрицательный, в зависимости от конкретных условий.
Пример построения простой репликации в MySQL
А сейчас настало время создать простую конфигурацию репликации в MySQL. Для этого мы будем использовать Docker и MySQL образы из dockerhub, а также базу данных world.
Для начала, запустим два контейнера, один из которых позже настроим как мастер, а второй — как слейв. Объединим их в сеть, чтобы они могли обращаться друг к другу.
Для мастер контейнера указано подключение volume c дампом world.sql, для того, чтобы имитировать наличие некоторой начальной базы на нем. При создании контейнера, mysql загрузит и выполнит sql скрипты, размещенные в директории docker-entrypoint-initdb.d.
Для работы с конфигурационными файлами, нам потребуется текстовый редактор. Можно использовать любой удобный, я предпочитаю vim.
Первым делом, создадим учетную запись на мастере, которая будет использоваться для репликации:
Далее, изменим конфигурационные файлы для мастер-сервера:
В файл my.cnf в секции [mysqld] необходимо добавить следующие параметры:
При включении/выключении двоичного журнала необходима перезагрузка сервера. В случае с Docker перезагружается контейнер.
Убедимся, что двоичный журнал включен. Конкретные значения, такие как имя файла и позиция, могут отличаться.
Для того, чтобы начать репликацию данных, необходимо “подтянуть” слейв до состояния мастера. Для этого, нужно временно заблокировать сам мастер, чтобы сделать слепок актуальных данных.
Далее, с помощью mysqldump сделаем экспорт данных из базы. Конечно, в данном примере можно использовать тот же world.sql, но приблизимся к более реалистичному сценарию.
После этого, необходимо еще раз выполнить команду SHOW MASTER STATUS, и запомнить или записать значения File и Position. Это, так называемые координаты двоичного журнала. Именно от них мы далее укажем стартовать слейву. Начиная с MySQL 5.6 стало возможным использование глобальных идентификаторов транзакций GTID вместо координат в виде файл-позиция. Это упростило настройку репликации, а также повысило стабильность ее работы. Но рассмотрение этой темы выходит за рамки данной статьи, и с ней можно ознакомиться в документации.
Теперь можем снова разблокировать мастер:
Мастер настроен, и готов реплицироваться на другие сервера. Перейдем теперь к слейву. Первым делом, загрузим в него дамп, полученный с мастера.
А затем изменим конфиг слейва, добавив параметры:
После этого перезагрузим слейв:
И теперь нам нужно указать слейву, какой сервер будет являться для него мастером, и откуда начинать реплицировать данные. Вместо MASTER_LOG_FILE и MASTER_LOG_POS необходимо подставить значения, полученные из SHOW MASTER STATUS на мастере. Эти параметры вместе называются координатами двоичного журнала.
Запустим воспроизведение журнала ретрансляции, и проверим статус репликации:
Если все прошло успешно, ваш статус должен иметь аналогичный вид. Ключевые параметры здесь:
- Slave_IO_State, Slave_SQL_State — состояние IO потока, принимающего двоичный журнал с мастера, и состояние потока, применяющего журнал ретрансляции соотвественно. Только наличие обоих потоков свидетельствует об успешном процессе репликации.
- Read_Master_Log_Pos — последняя позиция, прочитанная из журнала мастера.
- Relay_Master_Log_File — текущий файл журнала мастера.
- Seconds_Behind_Master — отставание слейва от мастера, в секундах.
- Last_IO_Error, Last_SQL_Error — ошибки репликации, если они есть.
Попробуем изменить данные на мастере:
И проверить, появились ли они на слейве.
Отлично! Внесенная запись видна и на слейве. Поздравляю, теперь вы создали свою первую репликацию MySQL!
Заключение
Надеюсь, что в рамках данной статьи мне удалось дать базовое понимание процессов репликации, ознакомить с применением данного инструмента, и попробовать самостоятельно реализовать простой пример репликации в MySQL. Тема репликации, и ее практического применения крайне обширна, и если вас заинтересовала данная тема, могу порекомендовать к изучению следующие источники:
- Доклад «Как устроена MySQL-репликация» Андрея Аксенова (Sphinx)
- Книга “MySQL по максимуму. Оптимизация, репликация, резервное копирование” — Бэрон Шварц, Петр Зайцев, Вадим Ткаченко
- «Хайлоад» — здесь можно найти конкретные рецепты по репликации данных
Надеюсь, что данная статья была полезна, и буду рад отзывам и комментариям!
Источник



