- Записки IT специалиста
- Squid — настраиваем URL-фильтрацию по спискам.
- To-do: Фильтруем вся и всё
- Анализ того, что такое есть интернет и как он работает.
- Cредства их осуществления.
- Где происходит фильтрация.
- Надёжность фильтрации.
- О недостатках уровней защиты.
- Возможность обхода пользователем контентной фильтрации.
- Вопрос-производительность.
- Вопрос-иерархия кэшей и прокси.
- Настройка локальной сети
- К нам идёт проверка.
Записки IT специалиста
Технический блог специалистов ООО»Интерфейс»
- Главная
- Squid — настраиваем URL-фильтрацию по спискам.
Squid — настраиваем URL-фильтрацию по спискам.
 Перед многими системными администраторами встает вопрос ограничения доступа пользователей к тем или иным ресурсам сети интернет. В большинстве случаев в ресурсоемкой и сложной контент фильтрации нет необходимости, вполне достаточно URL-списков. Реализовать такой метод вполне возможно средсвами прокси-сервера squid не привлекая стороннего ПО.
Перед многими системными администраторами встает вопрос ограничения доступа пользователей к тем или иным ресурсам сети интернет. В большинстве случаев в ресурсоемкой и сложной контент фильтрации нет необходимости, вполне достаточно URL-списков. Реализовать такой метод вполне возможно средсвами прокси-сервера squid не привлекая стороннего ПО.
Метод «черных» и «белых» списков идеально подходит для ограничения доступа к ресурсам, адреса которых заранее известны, но по какой-либо причине являются нежелательными, например социальные сети. По сравнению с контентной фильтрацией такой способ имеет множество недостатков, но с другой стороны он гораздо проще в реализации и требует гораздо меньше вычислительных ресурсов.
Эффективность данного метода следует рассматривать с точки зрения поставленной задачи, так если требуется заблокировать для сотрудников соцсети и ряд развлекательных ресурсов, на которых они проводят больше всего времени, то фильтрация по URL-спискам способна полностью решить эту проблему. В тоже время такая фильтрация окажется малоэффективной, если нужно ограничить доступ к любым ресурсам определенного содержания.
В дальнейшем мы будем подразумевать, что читатель обладает начальными навыками администрирования Linux. Также напомним, что все приведеные ниже команды следует выполнять от супрепользователя.
Прежде всего создадим файл списка. Располагаться он может в любом месте, но будет логично разместить его в конфигурационной директории squid — /etc/squid (или /etc/squid3 если вы используете squid3)
и приступим к его заполнению. При указании URL следует использовать RegExp синтаксис, мы не будем подробно останавливаться на этом вопросе, так как это выходит за рамки статьи, подробнее с правилами RegExp можно ознакомиться здесь. Для примера заблокируем популярные соцсети:
Обратите внимание, точка в RegExp является служебным симоволом и поэтому должна быть экранирована символом \ (обратный слеш).
В конфигурационном файле squid (/etc/squid/squid.conf) создадим acl список, в который включим хосты или пользователей, для которых будет производиться фильтрация.
В нашем случае фильтрация включена для всех хостов в диапазоне адресов 10.0.0.100-199, т.е. мы будем фильтровать интернет только для определенной группы пользователей.
Затем подключим наш список:
Ключ -i указывает на то, что список нечувствителен к регистру.
Теперь перейдем в секцию правил и перед правилом
Еще раз обратим ваше внимание, что все правила в squid обрабатываются последовательно, до первого вхождения, поэтому если мы разместим более общее правило перед более частным, то оно работать не будет. То же самое справедливо и для перекрывающихся правил — сработает самое первое.
Сохраним изменения и перезапустим squid:
Попробуем посетить сайт из списка, если все сделано правильно, то вы увидите сообщение squid о запрете доступа к данному ресурсу.
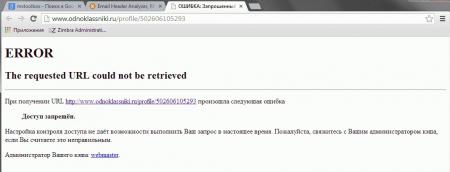 В дальнейшем вы можете дополнять списки, не забывая каждый раз после этого перезапускать squid.
В дальнейшем вы можете дополнять списки, не забывая каждый раз после этого перезапускать squid.
Рассмотрим немного иную ситуацию, требуется фильтровать интернет для всех, кроме определенной группы. В этом случае создадим acl для исключенных пользователей:
и изменим запрещающее правило следующим образом:
Также вы можете использовать несколько URL-списков и списков доступа, гибко регулируя доступ для разных групп пользователей.
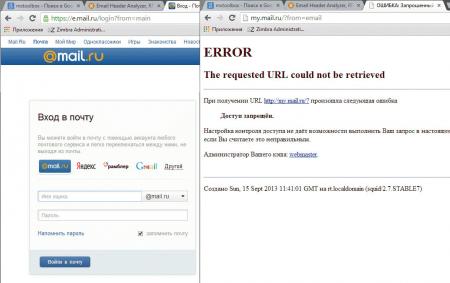
Вернемся к регулярным выражениям. Допустим, что нам нужно заблокировать не ресурс целиком, а его часть, тогда составим строку таким образом, чтобы она обязательно содержала нужную часть адреса, например строка:
Заблокирует доступ к социальной сети Мой мир, но не будет препятствовать доступу к Майл.ру.
 В качестве строки можно использовать не только доменное имя, но и его часть. Так если мы внесем в список простую строку
В качестве строки можно использовать не только доменное имя, но и его часть. Так если мы внесем в список простую строку
то это приведет к блокировке всех ресурсов, у которых данное сочетание входит в доменное имя, т.е. и mail.ru и hotmail.com. Поэтому к составлению списков, особенно содержащих короткие простые сочетания, нужно подходить осторожно.
Рассмотрим простой, но показательный пример. Допустим нужно заблокировать известный сайт auto.ru и его поддомены. Если мы, не долго думая, напишем
То вместе с требуемым порталом будут заблокированы все сайты имеющие данное сочетание в имени, например abc-auto.ru. Есть о чем задуматься. Если с поддоменами все просто, достаточно написать
и все что содержит точку перед искомым адресом будет заблокировано, то с основным доменом сложнее, самое время вспомнить про полный формат адреса:
Теперь будут заблокированы только адреса начинающиеся с http://auto.ru, конструкция (www\.)? обозначает, что префикс www c точкой могут быть, а могут не быть. Зато другие сайты, содержащие auto.ru будут нормально открываться.
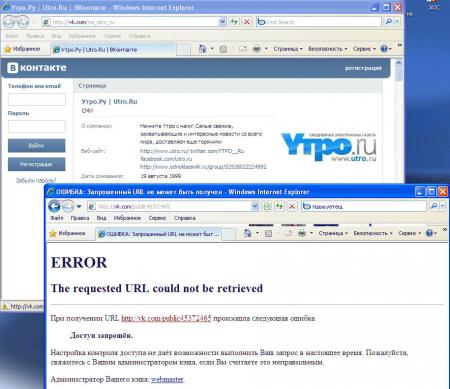
 Напоследок рассмотрим еще одну ситуацию, как сделать, чтобы на заблокированом сайте были доступны некоторые страницы. Например, страничка компании в Вконтакте или вы хотите обезопасить определенные адреса от случайного попадания под фильтр в будущем. Для этого следует добавить к системе «белый» список. Создадим файл списка:
Напоследок рассмотрим еще одну ситуацию, как сделать, чтобы на заблокированом сайте были доступны некоторые страницы. Например, страничка компании в Вконтакте или вы хотите обезопасить определенные адреса от случайного попадания под фильтр в будущем. Для этого следует добавить к системе «белый» список. Создадим файл списка:
внесем в него нужные адреса, для примера разблокируем страничку Вконтакте новостного портала Утро.ру:
и добавим правило перед запрещающим, в итоге должно получиться:
Так как разрешающее правило расположено раньше, то указанные в «белом» листе ресурсы будут доступны, несмотря на то, что будут попадать под правила «черного».
 Как видим, технология URL-фильтрации по спискам при помощи squid очень проста и позволяет в кратчайшие сроки ограничить доступ к нежелательным ресурсам, ниже приведен набор используемых нами списков, которыми вы можете воспользоваться.
Как видим, технология URL-фильтрации по спискам при помощи squid очень проста и позволяет в кратчайшие сроки ограничить доступ к нежелательным ресурсам, ниже приведен набор используемых нами списков, которыми вы можете воспользоваться.
Источник
To-do: Фильтруем вся и всё
Данная статья представляет из себя скорее более FAQ, чем полноценный мануал. Впрочем, многое уже написано на хабре и для того присутствует поиск по тегам. Смысла переписывать всё заново большого нет.
В последнее время наше государство, к счастью или не к счастью, принялась за интернет и его содержимое.
Многие, несомненно, скажут что нарушаются права, свободы и т.п. Конечно, думаю мало у кого возникнуть сомнения по поводу того, что то что придуманные законы сделаны мало понимающими людьми в деле интернетов, да и основная их цель это не защита нас от того, что там есть. Будучи ответственным человеком да подгоняемый и прокурорами в некоторых учреждениях, встаёт вопрос ограничения поступающей информации. К таким учреждениям, к примеру, относятся школы, детсады, университеты и т.п. им учреждения. Да и бизнесу то-же надо заботится об информационной безопасности.
И первый наш пункт на пути к локальному контент фильтру-это
Анализ того, что такое есть интернет и как он работает.
Не для кого не секрет, что 99 процентов интернета-это http. Далее известно, что у каждого сайта есть имя, содержания страницы, url, ip адрес. Известно, также, что на одном ip может сидеть несколько сайтов, как и наоборот. Так-же, url адреса могут быть как динамичны, так и постоянны.
А то, что записано на страничке, то написано. Отсюда делаем выводы, что сайты можно мониторить по:
- Имени сайта
- url страницы
- По содержанию написанного на страничке сайта
- По ip адресу.
Далее, весь контент в интернете можно разделить на три группы:
- Это плохое
- Это неизвестное
- Это хорошее.
И отсюда вытекает два идеологических пути:
- Разрешаем только то, что хорошее и запрещаем плохое и неизвестное. Данный путь носит название — БООЛЬШОЙ(а бывает и маленький) Белый список
- Разрешаем только то, что хорошее и неизвестное. Запрещаем только плохое. Данный путь носит гордое имя Чёрный список.
Ну и конечно между двумя этими путями существует золотая середина-запрещаем плохое, разрешаем хорошее, а неизвестное анализируем и в режиме онлайн выносим решение-плохо или хорошо.
Cредства их осуществления.
Тут опять два пути:
- Берём готовое решение.
Такие решения тоже бывают 3 видов-платные, бесплатные, ограниченные(пока не дашь денежку).
Платные решения-это аппаратные(тобишь коробка с неизвестно чем, но делающая своё дело), аппаратно-программные(это то-же коробка, но уже с полноценной ос и соответствующими приложениями) и программные.
Бесплатные решения-это только программные. Но бывают и исключения, но это как раз тот случай, подтверждающий правило.
К платным относятся такие, как Kaspersky антивирус соответствующего функционала, ideco.ru, netpolice, kerio и т.п. Найти их легко, ибо их хорошо рекламируют и достаточно в строке поиска ввести что-то вроде — контентный фильтр купить.
Бесплатные решения имеют один недостаток-они всё сразу делать не умеют. найти их затруднительнее. Но вот их список: PfSense, SmoothWall(бывает двух видов-платный и бесплатный. Бесплатный немного не функционален), UntangleGateway, Endian Firewall(тоже есть платный и бесплатный), IPCOP, Vyatta, ebox platform, Comixwall(Чудное решение. Можете скачать с моего сайта 93.190.205.100/main/moya-biblioteka/comixwall). Все данные решения обладают одним недостатком — ограниченность.
- Делаем всё руками.
Данный путь самый трудный, но самый и гибкий. Позволяет сотворить всё, что душа пожелает(в том числе и лазейку).
Тут есть великое множество компонентом. Но самые мощные и нужные это-
- Squid.Без прокси ни куда.
- Dansguardian. Это сердце всего контентного фильтра. Единственный ему бесплатный соперник(не считая его форков)-это POESIA фильтр(но он очень дремуч).
- DNS сервер Bind.
- Clamav. Антивирус.
- Squidguard, режик и им подобные редиректоры для прокси.
- Squidclamav.
- Sslstrip. Эта утилита делает из зашифрованного https трафика, расшифрованный http трафик.
www.thoughtcrime.org/software/sslstrip. Аналоги ей прокси-сервер flipper и charly proxy. Но работают аналоги на Windows. А второй платен. Но кому надо, то можно и wine развернуть. - Чёрные списки. Данные списки можно взять с www.shallalist.de (1,7 миллионов сайтов), www.urlblacklist.com (а именно версию big с более чем 10 миллионами сайтов), www.digincore.com (около 4 миллионов), списки режика.
- Белые списки. Тут всё очень туго. Единственный нормальный(значит-большой) русскоязычный список можно получить от лиги безопасного интернета, и то только в качестве proxy лиги безопасного интернета или программы www.ligainternet.ru/encyclopedia-of-security/parents-and-teachers/parents-and-teachers-detail.php?ID=532. Кстати в связи с digest авторизацией на прокси лиги, данный прокси не подцепить к squid. Если кто знает как подцепить в качестве родительского прокси, прокси сервер с digest аутентификацией, прошу сообщить.
- DNS списки. Тут есть два известный варианта. Первый-это skydns фильтр www.skydns.ru.
Второй-это yandex dns dns.yandex.ru.
Skydns более функционален, в отличии от яндекса.
Где происходит фильтрация.
Возможны следующие варианты:
- На компьютерах пользователя без централизованного управления, в качестве системного компонента или приложения.
- То-же, что и первое, но с централизованным управлением(как пример KASPERSKY ADMINISTRATION KIT).
- Компонент к браузеру. Есть для хрома и лиса соответствующие плагины
- На отдельном компьютере или кластере компьютеров(включая вариант-на шлюзе).
- Распределёнка.
1 и 2, 3 варианты с точки зрения быстроты фильтрации-самые быстрые при массовом использовании сети.
С точки зрения трудозатрат, 1 и 3-самые трудозатратные.
С точки зрения надёжности не обхода фильтрации пользователем, то 4-первое место.
5 вариант-мечта. Но его нет нигде.
Теперь следующий вопрос:
Надёжность фильтрации.
Думаю, ясно. Защиту нужно делать многоуровневой, ибо то, что просочится на одном уровне защиты, перекроется другим уровнем.
Давайте поговорим о
О недостатках уровней защиты.
- Списки
Интернет-это постоянно и главное-очень быстро меняющаяся среда. Понятно, что наши списки будут не поспевать за интернетом, а уж тем более если мы их будем вести руками. Потому участвуйте в сообществах составления списков и используйте не только файлы со списками, но и сервисами списков, где всё сделают за нас(пример — skydns и yandex).
Да и список не гарантирует того, что на какой-то страничке написано что-то не то, а сам сайт полностью белый и пушистый.
Используйте несколько списков. Что не попало в один, может попало в другой.
К программам, работающим по спискам относятся Netpolice(http://netpolice.ru), цензор(http://icensor.ru/), Traffic Inspector для школ(http://www.smart-soft.ru/ru ) и др. Обычно программы, умеющие делать лексический разбор, умеют работать и по спискам.
Цензор имеет старенькую базу от 2008 года. Но бесплатен во всем. Netpolice существует множество версий и есть бесплатная, но урезанная.
И не забываем-ни чёрные, ни белые списки не смогут вас оградить на 100%. На то способен только лексический анализ.
- Анализ на вирусы.
Тут главная проблема-антивирусные базы. Опять же, один антивирус на шлюзе, другой-на рабочем месте.
- Анализ содержания написанного на страничке.
Тут главная проблема — лексический разбор текста. На искусственный разум, понятно, денег нет ни у кого, потому используют базу слов и выражений с весовым коэффициентом. Чем меньше база-тем менее эффективна фильтрация, но и чем больше база, тем более она эффективна, но и трудозатратна. К примеру, разбор произведения Жюль Верна Таинственный остров с lib.ru занимает 8 секунд с моей базой и dansguardian(core2duo 2,66). Да и базу надо где-то взять. Нормальную базу мне пришлось делать самому, чем с вами и делюсь 93.190.205.100/main/dlya-dansguardian/spiski/view.
Возможность обхода пользователем контентной фильтрации.
Вопрос-производительность.
Тут более или менее всё ясно-больше памяти, больше герц, больше кэша. И очень полезно для тех, у кого мощности маленькие, использовать оптимизацию по CFLAGS. Это позволяют делать все линуксы и фряхи, но особо удобны gentoo, calculate linux, slackware, freebsd.
У кого многоядерные процессоры, то используйте OPEMNP(dansguardian пригодный для оного можете взять у меня 93.190.205.100/main/dlya-dansguardian. Кстати, в нём-же исправлена ошибка с невозможностью загрузки данных в интернет.) CFLAGS=»-fopenmp». LDFLAGS=»-lgomp». Не забудьте включить -O3 -mfpmath=sse+387. Про автопатчинг здесь.
Вопрос-иерархия кэшей и прокси.
Если у вас много компьютеров и вы имеете возможность использовать несколько в качестве фильтрации, то делайте так. На одном ставите прокси сервер squid и указываете на нём параметры родительских кэшей с параметром round-robin(http://habrahabr.ru/post/28063/). В качестве родительских на каждом конкретном компьютере выступает выступает dansguardian со squid в связке(ибо без вышестоящего dansguardian не умеет). Вышестоящие располагаются на тех-же компьютерах, на которых располагаются и dansguardians. Для вышестоящих большой кэш не имеет смысла делать, а для первого-обязательно самый большой кэш. Даже если у вас одна машина, то на ней всё-равно делайте связку squid1->dansguardian->squid2->провайдер с таким-же распределением кэширования. На dansguardian не возлагайте ничего, кроме анализа написанного на страницах, перерисовки контента, заголовков и некоторых url, блокировки mime типов. Не в коем случае не вешайте на него антивирус и чёрные листы, иначе будут тормоза.
Анализ по спискам пусть будут делать squid1 и squid2.
Проверку на вирусы пусть будет делать squidclamav через c-icap на squid2. Белые списки вешаем на squid1.
Всё, что в белом списке, должно идти напрямую в интернет, минуя родительские прокси.
DNS сервер обязательно используем свой, в котором используем перенаправление на skydns или dns от yandex. Если есть локальные ресурсы провайдера, то добавляем зону forward на dns провайдера. Так-же в dns сервере прописываем локальную зону для нужных внутрисетевых ресурсов(а что-бы было красиво, они нужны). Указываем nosslsearch поиска google. В конфигах squid обязательно используем свой dns.
Для всего используем вебку Webmin и командную строчку. На windows серверах всё делаем через мышку.
Настройка локальной сети
- Используйте аутентификацию по ip адресам. Если вы не «серьёзная» организация, доступ с обязательным логинированием ни к чему.
- Используйте логически разделённые сети в одной сплошной физической сети. IP адреса выдавайте по MAC адресам. Запрещайте коннект на порт прокси-сервера при несовпадении MAC адреса машины с присвоенному данному MAC адресу, IP адреса.
- Настройте iptables таким образом, чтобы обращения на любые порты(3128, 80, 80, 3130, 443) шло через порт прокси сервера.
- Настройте автоматическую настройку прокси-сервера в сети через dns и dhcp. www.lissyara.su/articles/freebsd/trivia/proxy_auto_configuration
- Группы и уровень фильтрации делайте по ip адресу.
- Можно настроить прокси в настройках браузера.
К нам идёт проверка.
В данном случае-все ползунки в максимум.
Дополнительно-запрещаем все видеосайты, контакт, социальные сети, музыкальные порталы, файлообменники и файлообменные сети.
Запрещаем mp3.
Ставим галочку напротив безопасного поиска в личном кабинете SKYDNS.
Обязательно приводим в порядок документацию.
Источник



