- Производительность VM VmWare Workstation на отдельном жёстком диске
- Предыстория
- Замысел
- Тестирование
- Результаты
- Как ускорить работу виртуальной машины
- Фиксированный размер диска
- Используйте дополнения гостевой ОС
- Особенности использования антивирусов
- Проверьте настройки виртуальной машины вручную
- Оперативная память
- Процессор
- Дисплей
- Установка виртуальной машины на SSD
- Файл подкачки и автозагрузка
- Производительность VMware vSphere 5.5 и 6.0 — настройки, соображения. Perfomance Best Practices
- Хост ESXi
- Виртуальные машины
- Гостевая ОС
- Хранение и хранилища
- Инфраструктура виртуализации
Производительность VM VmWare Workstation на отдельном жёстком диске
Предыстория
Занимаясь разработкой и тестированием ПО, в т.ч. дома, приходится разворачивать виртуальную среду и устанавливать специализированное ПО как то: среды разработок, серверы базы данных, приложений и др. Вплоть до развёртывания полноценной тестовой среды. В моём случае у меня живёт целый домен AD с блекджеком клиентами с разными ОС, БД, брандмауэром, IIS и др. В случае, если всё это собрано на технике домашнего уровня, ощущается замедление производительности, особенно при работе с дисковой подсистемой. Конечно же, в случае однопользовательской нагрузки никаких проблем и зависаний, можно и подождать несколько секунд в большинстве случаев. Но в некоторых случаях снижение производительности уже капитально меня достало, в частности при работе в Visual Studio.
Замысел
РазвлекаясьРаботая с VmWare Workstation уже много лет, помнил, что при создании VM можно выбрать отдельных жёсткий диск для хранения данных:
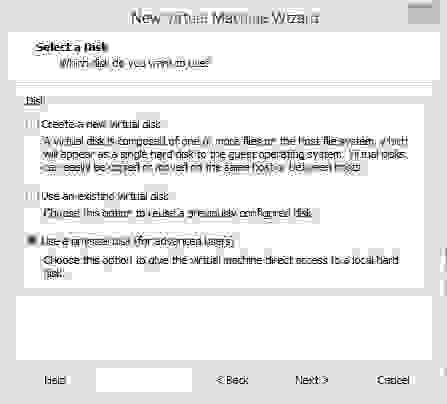
Беглый поиск по сети не дал точных количественных оценок прироста производительности. Только общие рекомендации: то, что «наверное будет работать быстрее» и зависеть от конкретного железа, типов тестов и работы в VM. Решил попробовать развернуть там VM Windows 2012R2 и провести тесты скорости работы с диском сам, а также посчитать скорость загрузки VM с запуском Visual Studio 2013 и открытием проекта в ней. И для полноты картины расширить виды тестирования — провести аналогичные замеры при расположении VM на домашнем сетевом хранилище и в разных виртуальных машинах (VmWare и Virtual Box). Вдруг где-нибудь будут выдающиеся результаты?
Тестирование
Наборы тестирования
Итак, необходимо проверить следующие тесты:
- CrystalDiskMark
- Время запуска VM с открытием проекта в Visual Studio
Скомбинировав это с 5 разновидностями типов и конфигураций VM (VmWare и VirtualBox локально и по сети, VmWare на отдельном диске), получаем 10 тестов. Virtual BOX ещё не умеет работать с отдельными дисками/разделами.
Аппаратное окружение
ОС Windows 8.1;
VmWare Workstation 10.0.6;
Virtual BOX 5.0.16;
Intel Core i7 4core;
MB Asus P6X58D-E;
24 Gb RAM;
HDD: 256 Gb SSD для ОС;
HDD для VM: Segate Barracuda ST3250318AS, SATA-II, 8Mb, 7200rpm.
ОС Windows 2012R2;
Intel Core i3 2core;
MB Asus P8H61-I;
4 Gb RAM;
HDD Seagate Constellation ES ST1000NM0011 SATA-III, 64 Мб, 7200rpm.
Используются встроенные в MB сетевые контроллеры, сеть между машинами 1 Гбит/с. Диски на хост-машине и в хранилище разные, это конечно может повлиять на результаты. Но запуск по сети тут являются не основной целью, поэтому перекручивать диски между хост-машиной и сетевым хранилищем я не стал.
ОС в во всех VM устанавливается с нуля, устанавливаются тулзы от VM, Visual Studio. в VM копируется и 1 раз открывается проект Visual Studio. При последующей перезагрузке измеряются показатели.
В случаях VMDK и VDI файлов разбивать на несколько не стал, вся VM хранится в одном файле.
Результаты
WmWare Workstation, VMDK на локальном диске (слева) и в сетевом хранилище (справа):

Virtual BOX, VDI на локальном диске (слева) и в сетевом хранилище (справа):

И долгожданное измерение, VmWare машина, использующая целый отдельный диск:

Как видно практически не отличается от запуска VM с хранением VMDK-файла на этом же диске. Т.е. никакого заметно прироста нет, всё в рамках погрешности. А что со временем запуска данных VM, открытием проекта в Visual Studio 2013 и открытии на редактирование файла в ней? Под проект я взял маленький сайт на ASP.NET размером 13 Мб, 161 файл. Открывал default.aspx из корня сайта.
| Тест | VmWare LocalVMDK | VmWare отдельный диск | VmWare по сети | VirtualBOX LocalVDI | VirtualBOX по сети |
| Запуск VM с VS, мин: сек | 2:15 | 1:57 | 1:55 | 1:54 | 2:22 |
Как видно, небольшой выигрыш в скорости при использовании отдельного диска есть (выделено жирным). Разброс в показаниях по другим тестам и их выигрыш по сравнению с отдельным диском объяснить без более когерентной среды невозможно (перекручивать диски как минимум надо).
Также возник вопрос: как может влиять SSD диск в хост-машине на результаты? Ведь сами настройки VM я положил на него. И там при работе ОС лежит VMEM файл размером 2 Гб.

Понаблюдал за обращениями к SSD с настройками VM и этим VMEM файлом во время работы VM с отдельным диском. Ну вроде как обращений к SSD нет, 0-1% загруженности диска. Вот пример — момент инсталляции такой VM. Диск D используется под потолок, SSD не используется:

Всё-таки решил уйти от SSD и сохранить настройки VM и VMEM файл на том же диске, куда и замаплен VMDK. Так, чтобы этот диск взял на борт всю VM с потрохами. При создании VM и выборе отдельного диска есть возможность использовать не целый диск а Use individual partition на этом диске. Разбил диск на 2 части, немного (30 Гб) выделил подраздел для хранения настроек VM, а остальной RAW раздел отдал VM:

VM нормально создаётся, настройки сохраняются в видимый в хостовой ОС раздел. Но когда дело доходит до записи данных в раздел, всецело отданный для VM, появляется ошибка невозможности записи в него и VM выключается. Победить эту ошибку к сожалению не удалось, в чём дело не понятно.
Визуальные ощущения
По числам не видно, но время отклика интерфейса заметно выше, чем при работе с VMDK/VDI на том же диске или в сети.
Источник
Как ускорить работу виртуальной машины

Чтобы виртуальные машины VirtualBox , VMware Workstation или Hyper-V работали стабильно и без зависаний, в их распоряжении должно быть достаточное количество ресурсов, в первую очередь ресурсов центрального процессора и оперативной памяти. Запускать ВМ можно и на компьютерах малой и средней (2-4 Гб ОЗУ) мощности, но в этом случае рассчитывать на комфортную работу в виртуальной операционной системе не стоит.
Тем не менее, грамотная оптимизация BM позволит вам увеличить производительность последней без оказания существенного влияние на хостовой компьютер.
Фиксированный размер диска
Используйте фиксированный размер виртуального диска.
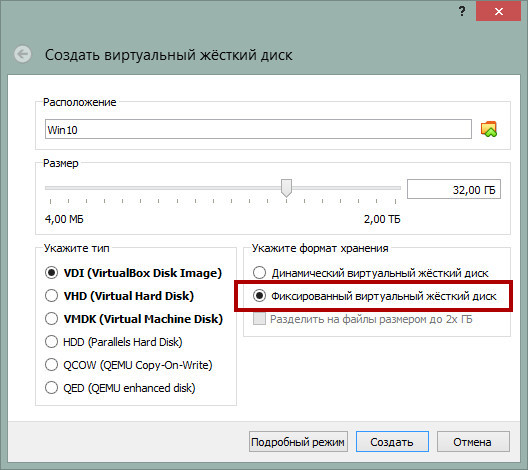
Большинство систем виртуализации по умолчанию создают динамические диски, увеличивающиеся по мере «разрастания» установленной на них операционной системы. С одной стороны, использования такого типа контейнеров позволяет экономить место на физическом диске, однако установленная на динамический диск система работает медленнее, причем ее производительность падает с увеличением последнего.
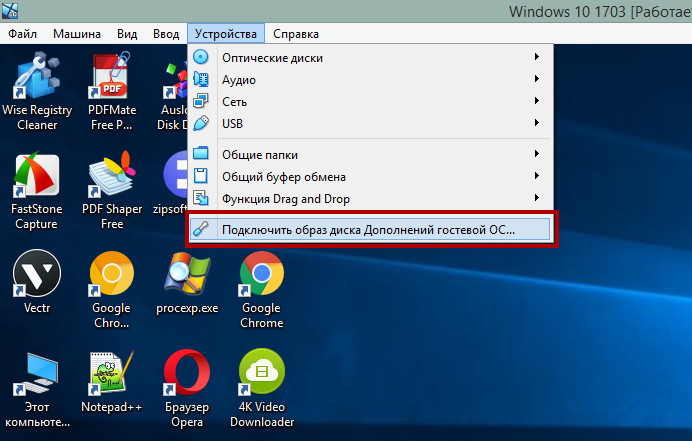
Используйте дополнения гостевой ОС
Даже если вы не собираетесь пользоваться общими папками, буфером обмена и другими опциями расширения функциональности, не пренебрегайте установкой дополнений гостевой ОС, их инсталляция в систему обеспечивает более эффективное использование ресурсов хостовой машины.
Особенности использования антивирусов
Не устанавливайте в гостевую операционную систему антивирусных программ, в этом нет никакой необходимости, заботиться нужно о безопасности не виртуальной, а хостовой системы. Отключите в виртуальной ОС встроенную защиту, если не собираетесь использовать ее в рамках тестирования. Рекомендуем также добавить весь каталог с ВМ в исключения вашего антивируса.
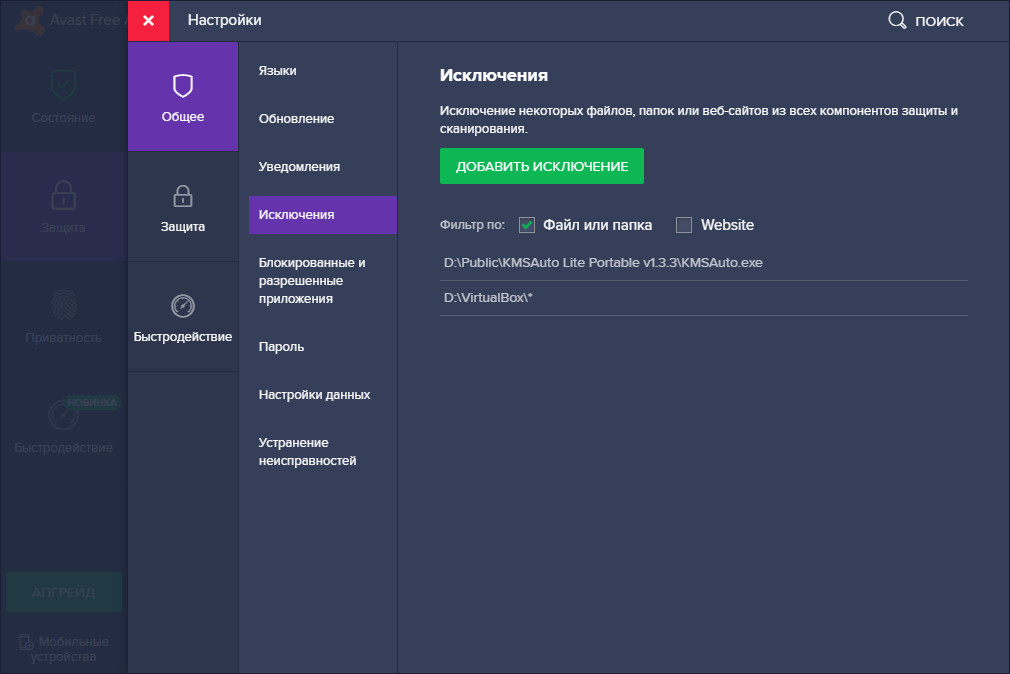
Сканирование контейнера с ВМ не только замедляет ее работу, но и не приносит никакой пользы с точки обнаружения вредоносного ПО внутри виртуального контейнера.
Проверьте настройки виртуальной машины вручную
Что касается установленных по умолчанию параметров виртуальной машины, здесь нужно действовать по принципу «доверяй, но проверяй».
Зайдите в настройки вашей ВМ и и проверьте эти параметры:
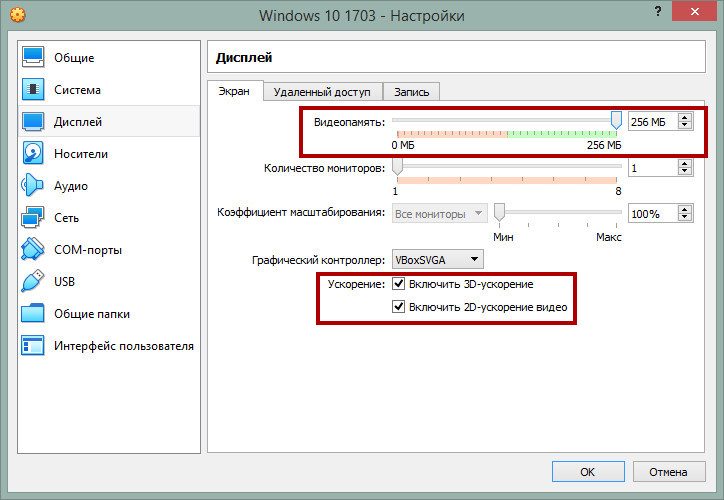
Оперативная память
Увеличьте, если возможно, объем выделенной ОЗУ до 2 Гб.
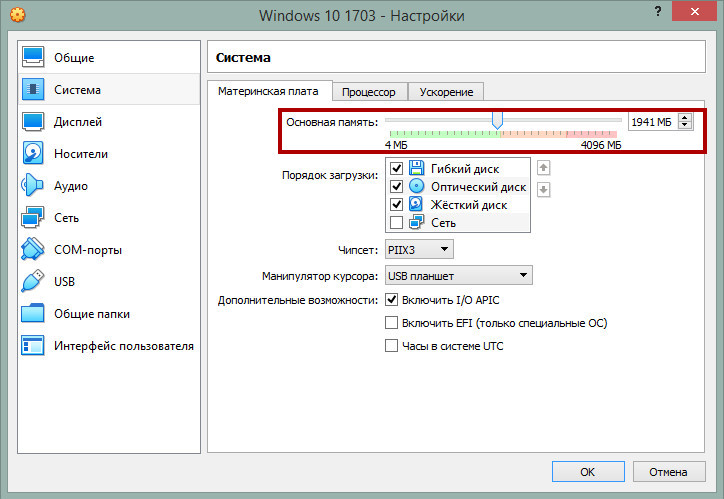
Процессор
Выделите максимально допустимое количество ядер процессора и убедитесь, что в пункте PAE/NX стоит галочка. Если в вашей системе виртуализации доступны функции Nested VT-х/AMD-v, включите их, они улучшают виртуализацию.
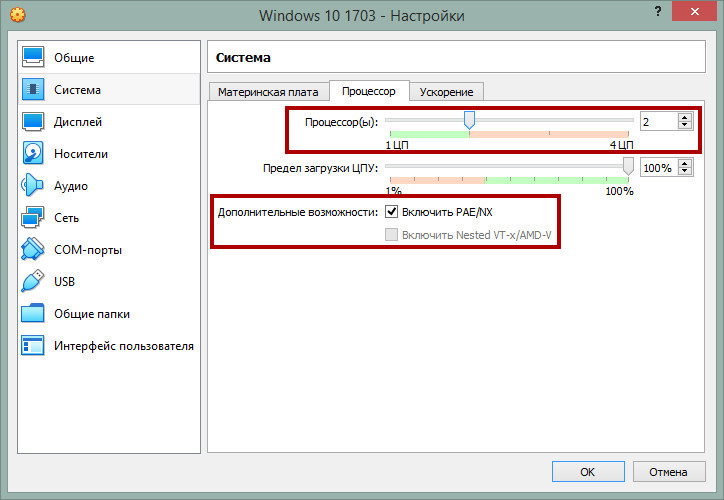
Дисплей
Выделите виртуальной машине максимальный объем видеопамяти и включите, если выключено, ускорение 2D и 3D.
Установка виртуальной машины на SSD
Если у вас есть SSD -диск, устанавливайте виртуальную машину на него, это существенно ускорить ее работу, однако SSD должен быть подключен непосредственно к материнской плате, а не по USB , в противном случае существенного прироста скорости вы не ощутите. В крайнем случае можно подключить внешний SSD -диск с виртуальной машиной по USB 3.0 и выше, но никак не по USB 2.0 .
Файл подкачки и автозагрузка
Не стоит пренебрегать и внутренней оптимизацией. Для увеличения производительности виртуальной машины используйте внутри нее файл подкачки, особенно на популярных Linux-системах. Размер файла свопа в данном случае определяется общими правилами.
К внутренней оптимизации также следует отнести отключение неиспользуемых элементов автозагрузки, визуальных эффектов, фоновых приложений, службы автоматического обновления системы и индексирования.
На HDD -дисках рекомендуется выполнять внутреннюю дефрагментацию файлов операционной системы. Придерживаясь этих простых рекомендаций, можно, пусть и ненамного, увеличить производительность и отзывчивость виртуальной машины.
Источник
Производительность VMware vSphere 5.5 и 6.0 — настройки, соображения. Perfomance Best Practices

Проштудировав документы Perfomance Best Practices for vSphere 5.5 и Perfomance Best Practices for vSphere 6.0, не выявил особых расхождений в настройке, как и чего-то дополнительно специфичного для vSphere 6.0.
Большая часть написанного умещается в стандартные рекомендации формата «используйте совместимое и сертифицированное оборудование» и «при сайзинге ВМ выделяйте ресурсы (vCPU, vRAM) в объёме не более необходимого».
Тем не менее, базовые вещи решил оформить отдельным постом, немного переструктурировав, избавив от «воды» и некоторых отсылок и замечаний, которые являются слишком специфичными и для большинства реализаций являются скорее вредными чем полезными. В сухом остатке остались рекомендации, советы и соображения, проверенные и протестированные на практике и применимые для 90% инфраструктур VMware vSphere и standalone ESXi. Разбавленные общими соображениями и дополнениями.
Хост ESXi
Общие рекомендации
- Ну понятно, стоит использовать совместимое оборудование. Процессоры с аппаратной поддержкой виртуализации. Процессоры в разных хостах кластера должны быть минимум одного производителя (Intel/AMD) а желательно и одного уровня технологий и поколения. Иначе проблемы с vMotion и производительностью. И желательно вообще единообразие в аппаратной конфигурации кластера — проще управлять (Host Profiles) и диагностировать.
- Установить свежие версии BIOS и firmware на все «железки». Не обязательно это скажется на росте производительности, но в случае проблем на стыке железо-софт техподдержка вендора всё равно будет требовать обновления прошивок. Мы с IBM так почти год чинили Blade-корзину — пока обновили прошивки на всех задействованных и не очень компонентах, они выпустили их новые версии и пришлось идти по второму кругу.
Гипервизор
Тут стоит иметь ввиду, что и по процессору и по памяти для каждой виртуальной машины есть определённый оверхед — дополнительное количество того и другого, необходимое для работы самой ВМ:
— для процесса vmx (VM eXecutable);
— для процесса vmm (VM Monitoring) — мониторинг состояния виртуального процессора, маппинг — виртуальной памяти и т.д.;
— для работы виртуальных устройств ВМ;
— для работы других подсистем — kernel, management agents.
Оверхед каждой машины более всего зависит от количества её vCPU и объёма памяти. Сам по себе он не большой, но стоит иметь ввиду. Например, если весь объём памяти хоста будет занят или зарезервирован виртуальными машинами, то может увеличиться время отклика на уровне гипервизора, а также возникнут проблемы с работой таких, например, технологий как DRS.
Виртуальные машины
Главная рекомендация — сайзинг по минимуму. В смысле — выделять виртуальной машине не больше памяти и процессоров, чем ей реально нужно для работы. Ибо в виртуальной среде больше ресурсов зачастую приводят к худшей производительности, чем меньше. Это сложно понять и принять сразу, но это так. Основные причины:
— оверхед, описанный в предыдущем разделе;
— NUMA. Если количество vCPU соответствует количеству ядер в NUMA-сокете и объём памяти тоже не выходит за пределы NUMA-ноды, то гипервизор старается локализовать ВМ внутри одной NUMA-ноды. А значит доступ к памяти будет быстрее;
— Планировщик процессора. Если на хосте много ВМ с большим количеством vCPU (больше в сумме, чем количество физических ядер), то растёт вероятность появления такого явления как Co-Stop — притормаживание некоторых vCPU из-за невозможности обеспечить их синхронную работу в рамках отдельной ВМ, потому что количества физических ядер не хватает для одновременного цикла;
— DRS. Машины с небольшим количеством процессоров и памяти переносить с хоста на хост проще и быстрее. В случае внезапного скачка нагрузки легче будет перебалансировать кластер, если он состоит из небольших ВМ, а не из многогигабайтных монстров;
— Локализация кэша. Внутри ВМ гостевая ОС может переносить однопоточные процессы между различными процессорами и терять процессорный кэш.
Выводы и рекомендации:
- Лучше один процессор, загруженный на 80%, чем 4 по 20%.
- Если у сервера пиковая загрузка происходит раз в квартал, а в остальное время он работает на 10% своих ресурсов, лучше урезать их (ресурсы) сразу в 8 раз, а раз в квартал добавлять необходимое количество.
- Стараться умещать ВМ по количеству vCPU и памяти в границы NUMA-node.
- Если ВМ выходит за пределы NUMA-ноды (wide VM), конфигурировать число процессоров кратное числу ядер в NUMA-ноде. Если у нас в одном сокете 4 ядра, то кратные числа процессоров, рекомендуемые для ВМ будут 4, 8, 12.
- При использовании нескольких vCPU, лучше конфигурировать их как отдельные виртуальные сокеты с одним виртуальным ядром в каждом. Ну или с количеством ядер, являющимся целым делителем от числа ядер в NUMA. Если в физическом сокете 4 ядра, то в виртуальном правильным значением будет 1, 2, 4. Но не 3 или 6.
- Отключать неиспользуемое виртуальное оборудование виртуальной машины (COM-, LPT-, USB-порты, Floppy Disks, CD/DVD, сетевые интерфейсы и т.д.)
- Использовать паравиртуальное оборудование (VMware Paravirtual для SCSI-контроллера и VMXNET для сетевого адаптера). Это уменьшает нагрузку на процессор и время отклика, но может потребовать драйвера для установки ОС.
Гостевая ОС
- Использовать последние версии VMware Tools. После каждого обновления ESXi приводить в соответствие.
- И вообще иметь установленными VMware Tools.
- Отключать screen saver’ы и вообще любую анимацию и красивости. По возможности отключать графику. Это значительно снижает нагрузку на процессор.
- Избегать одновременного запуска интенсивных задач (таких как антивирусное сканирование, бэкапы и особенно дефрагментация). Дефрагментацию лучше вообще отключить. Остальное, если нельзя избежать, размазывать для разных машин в разное время.
- Синхронизировать время гостевой ОС с помощью ntp-сервисов или VMware Tools, но не обоих инструментов сразу. Но хотя бы одним. Так как стоит иметь ввиду, что время в гостевой ОС — не точная величина, поскольку зависит от процессора, а процессорного ресурса ВМ может получать не равномерно и не всегда в нужном объёме.
- vNUMA. Стоит принимать во внимание, что для ВМ с количеством vCPU большим восьми активируется проброс NUMA-архитектуры внутрь ВМ. Для некоторых NUMA-awared приложений, например, Exchange или MS SQL это полезно. Однако vNUMA определяется при первой загрузке ОС и не меняется, пока не изменится количество процессоров. Поэтому, если в кластере наличествуют хосты с разным количеством ядер в сокетах, а значит с разной NUMA-архитектурой, то при переезде ВМ с хоста на хост, производительность может падать из-за того что vNUMA не совпадает с NUMA на новом хосте.
Хранение и хранилища
Главное, что стоит принять во внимание — ваше хранилище должно поддерживать vStorage API for Array Integration (VAAI). В этом случае будет поддерживаться следующее:
— Оффлоад процессов копирования, клонирования и переноса ВМ между LUN одного хранилища или между хранилищами, поддерживающими технологию. То есть процесс будет выполняться большей частью самим хранилищем, а не процессором хоста и сетью.
— ускорение зануления блоков при создании Thick Eager Zeroed дисков и при первичном наполнении Thick Lazy Zeroed и Thin дисков.
— Atomic Test and Set (ATS) — блокирование не всего LUN, при изменении метаданных, а только одного сектора на диске. Учитывая, что метаданные изменяются при таких процессах как включение/выключение ВМ, миграция, клонирование и расширение тонкого диска, LUN с большим количеством ВМ на нём может не вылезать из SCSI Lock’а.
— Unmap — «освобождение» блоков тонких LUN при удалении/переносе данных (касается только LUN, но не vmdk).
Соображения и рекомендации:
- Independent Persistent Mode vmdk-диска — наиболее производительный, поскольку изменения вносятся сразу на диск, не журналируясь. Но такой диск не подвержен снапшотам, его нельзя откатить.
- При использовании iSCSI рекомендуется настроить jumbo frames (MTA=9000) на всех интерфейсах и сетевом оборудовании.
- MultiPathing — для большинства случаев RoundRobin — ОК. Fixed может дать большую производительность, но это после вдумчивого планирования и ручной настройки каждого хоста до каждого LUN. MRU можно поставить при active-passive конфигурации, если какие-то пути время от времени пропадают — чтобы не перескакивало туда-обратно.
Инфраструктура виртуализации
DRS и кластеры
- Для управления ресурсами и контроля их использования, лучше использовать Shares в большей мере, а Limits и Reservation — в меньшей. Лимиты жёстко ограничивают ВМ, даже если кластер имеет свободные ресурсы. Резервирование, напротив, отъедает много ресурсов, даже если они не используются. Кроме того, при апгрейде физического оборудования настройки Shares автоматически распределяют новые мощности пропорционально. А забытые лимиты и резервирование могут привести к тому, что часть машине недополучает ресурсов, хотя в кластере их уже более чем достаточно.
- Не стоит сооружать сложные многоступенчатые иерархические конструкции из Resource Pools. Для иерархий есть папки. А также держать на одном уровне (например, в корне) и Resource Pools и виртуальные машины. Потому что расчёт Shares для этих типов объектов производится по разному и могут появляться непредвиденные перепады производительности.
- Ещё раз — чем ближе хосты друг другу по конфигурации, тем лучше. В идеале — в кластеры все хосты однотипные. Без EVC даже на хосты с процессорами одного вендора, но разным набором технологий ВМ перемещаться смогут только в выключенном состоянии.
vMotion и Storage vMotion
По умолчанию, на каждый активный процесс vMotion гипервизор отъедает 10% одного ядра процессора. И на приёмнике и на источнике. То есть если на хосте все процессорные ресурсы находятся в резервировании, с vMotion могут быть проблемы. (С DRS точно будут).
При Storage vMotion с исходного датастора активно идёт чтение, а на целевой — запись. Кроме того, на оба датастора идёт синхронная запись изменений внутри ВМ. Отсюда вывод — если двигаем ВМ с медленного датастора на быстрый, эффект будет заметен только по окончанию миграции. А если с быстрого на медленный, то деградация производительности наступит сразу.
Источник



