- Настроить файн ридер без распознавания
- Полезные советы на все случаи в жизни
- Электронный журнал полезных советов, советы без воды и по сути. Пишут и делятся советами простые и открытые люди которым есть чем безвозмездно поделиться
- Всем привет! решил написать небольшую заметку для тех у кого стоит задача сканировать огромную гору документов, а Finereader после сканирования упорно твердит, что нужно сперва распознать страницу перед сохранением и конечно это не может не раздражать, это даже очень и очень сильно начинает бесить, когда с одной стороны начальник стоит над душой и ждёт когда же вы отдадите ему нужный сканированный вариант документов, с другой стороны сканер несмотря на свою производительность и все свои способности начинает тупить и Finereader не даёт сохранить нужные документы и конечно системный администратор как всегда занят и когда он подойдет до вас, вас либо уже уволят или вы разобьёте монитор и сканер , которые не желают исполнить задание.
- Нравится? Поделись с друзьями в социальных сетях, нажми поделиться
- Для уставших от офисных задач, предлагаю оценить фотографии девушек естественной красоты (50 фото)
- Укрощение строптивого (на самом деле, нет) FineReader
- Как пользователю поучаствовать в обработке документа
- Хорошо распознаются только хорошие изображения
- Этап настройки документа/проекта
- Этап анализа
- Назначение областей разных типов
- Важные соображения
- Особенности взаимодействия близкорасположенных или пересекающихся областей
- Маленькие хитрости для облегчения работы с блоками
Настроить файн ридер без распознавания
Правильно установленные параметры распознавания помогут вам быстро получить качественный документ, пригодный для дальнейшего редактирования. Выбор параметров зависит не только от объема и сложности исходного документа, но и от того, как вы намерены использовать распознанный документ.
Выбрать необходимые параметры вы можете на закладке Распознать диалога Опции (меню Сервис>Опции…).
Внимание! Распознавание страниц, добавленных в документ ABBYY FineReader, выполняется в автоматическом режиме с текущими настройками программы. Вы можете отключить автоматический анализ и распознавание добавленных изображений на закладке Сканировать/Открыть диалога Опции (меню Сервис>Опции…).
Замечание. Если вы изменили язык распознавания, выделили области на изображении вручную или изменили другие настройки программы, выполните распознавание заново.
На закладке Распознать диалога Опции вы можете изменить настройки для следующих групп опций:
Режим распознавания
Выберите один из режимов распознавания.
 Подробнее.
Подробнее.
В ABBYY FineReader 10 предусмотрено два режима распознавания:
- Тщательное распознавание
Данный режим пригоден для распознавания как простых, так и сложных документов. Например, для документов, содержащих текст на цветном фоне, или для документов, содержащих таблицы, в том числе таблицы без линий сетки и таблицы с цветными ячейками.
Замечание. По сравнению с Быстрым режимом распознавания, Тщательный режим требует больше времени, но обеспечивает лучшее качество распознавания.
Данный режим рекомендуется для обработки больших объемов документов с простым оформлением и хорошим качеством печати.
Для выбора режима распознавания в группе Режим распознавания выберите одну из опций: Тщательное распознавание или Быстрое распознавание.
Обучение
По умолчанию режим Распознавание с обучением отключен. Для того чтобы в процессе распознавания проводилось обучение неизвестным символам, отметьте опцию Распознавание с обучением.
Подробнее.
Распознавание с обучением используется для распознавания следующих текстов:
- Для набора которых использованы декоративные шрифты
- В которых встречаются специальные символы (например, отдельные математические символы)
- Большого объема (более 100 страниц) текста плохого качества
При распознавании вы можете использовать встроенные эталоны или создать собственный эталон. Для этого выберите нужную опцию в группе Обучение.
Источник
Полезные советы на все случаи в жизни
Электронный журнал полезных советов, советы без воды и по сути. Пишут и делятся советами простые и открытые люди которым есть чем безвозмездно поделиться
Всем привет!
решил написать небольшую заметку для тех у кого стоит задача сканировать огромную гору документов, а Finereader после сканирования упорно твердит, что нужно сперва распознать страницу перед сохранением и конечно это не может не раздражать, это даже очень и очень сильно начинает бесить, когда с одной стороны начальник стоит над душой и ждёт когда же вы отдадите ему нужный сканированный вариант документов, с другой стороны сканер несмотря на свою производительность и все свои способности начинает тупить и Finereader не даёт сохранить нужные документы и конечно системный администратор как всегда занят и когда он подойдет до вас, вас либо уже уволят или вы разобьёте монитор и сканер , которые не желают исполнить задание.
На самом деле всё предельно просто, нужно просто перестать видеть перед глазами цветные картинки кнопок Finereader и нажать пару других кнопок.
Решил всё как всегда описать в скринах и видео, думаю лучше один раз увидеть , чем сто раз прочитать.
Решено: Полная инструкция «Как сохранить в Finereader без распознавания» в скринах:
Нравится? Поделись с друзьями в социальных сетях, нажми поделиться
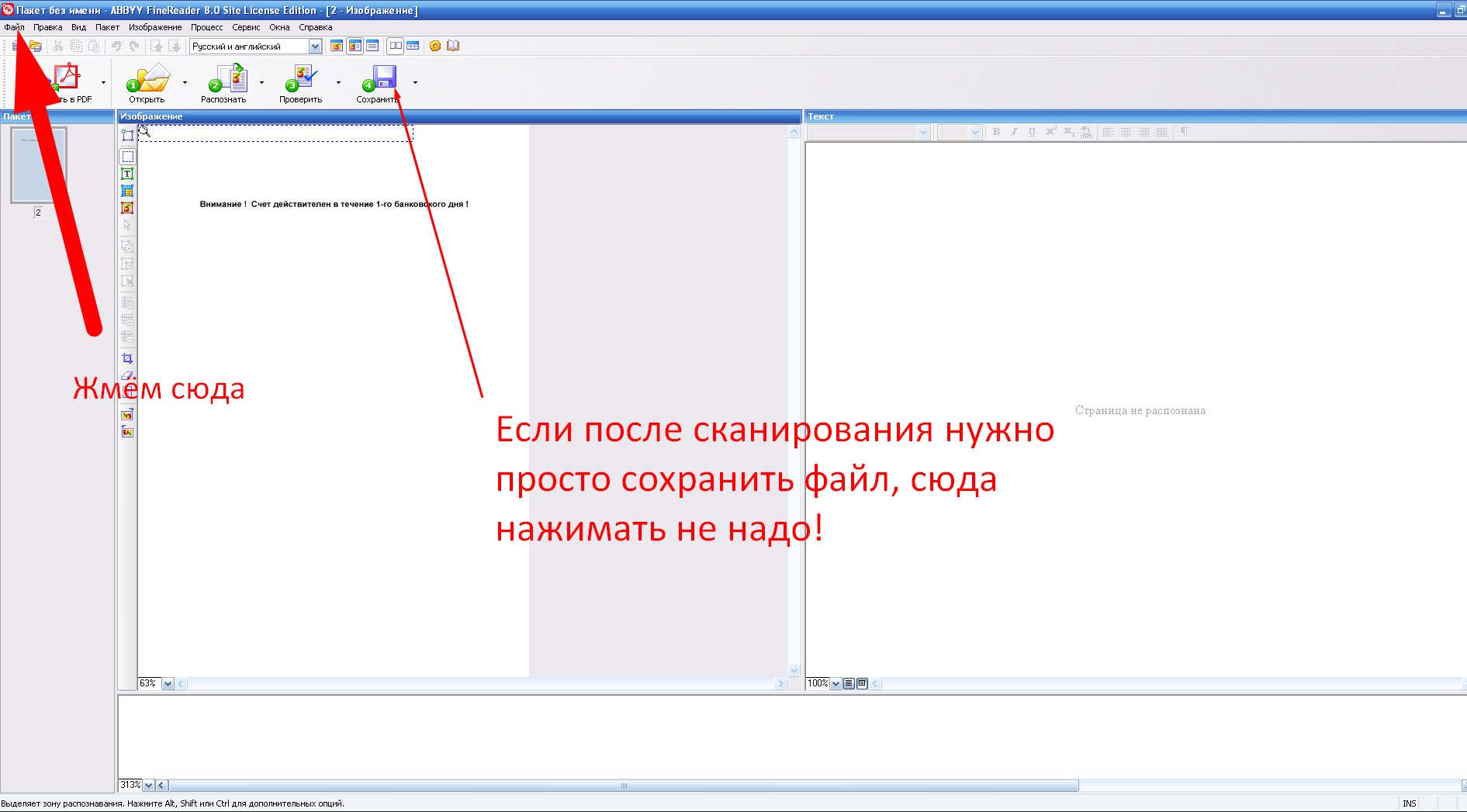
После того, как открыли Finereader
Отсканировали документ
Не нажимаем на яркие кнопки «Сохранить»
переходим к следующему скрину

Идем в левый верхний угол и нажимаем «Файл»

Далее нажимаем «Сохранить результаты»
После «Сохранить изображение»

Теперь уже почти на финише, выбираем нужный формат будущего файла
переходим на следующий скрин
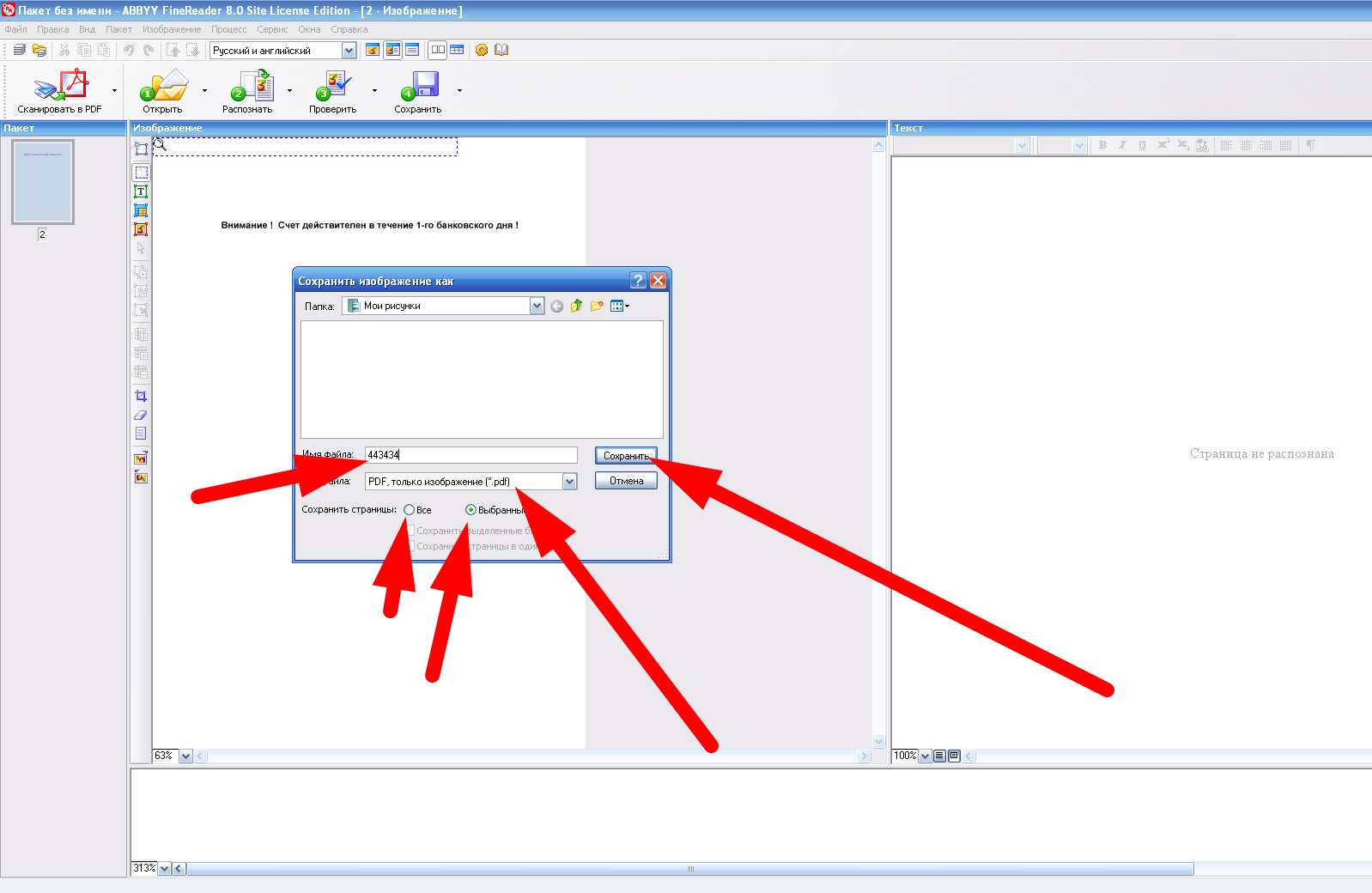 Называем файл, выбираем место для сохранения, выбираем вариант сохранения всех листов или выбранных и нажимаем кнопку «Сохранить»
Называем файл, выбираем место для сохранения, выбираем вариант сохранения всех листов или выбранных и нажимаем кнопку «Сохранить»
Видео инструкция о том, как сохранить отсканированные файлы в Finereader:
Для уставших от офисных задач, предлагаю оценить фотографии девушек естественной красоты (50 фото)
Девушек из свежей подборки можно объединить одним — натуральной красотой. С одной стороны вроде они все разные и отличаются друг от друга, но у каждой есть, что то удивительно прекрасное, что заставляет любоваться снова и снова. Смотрим и искренне восхищаемся.
Источник
Укрощение строптивого (на самом деле, нет) FineReader

После короткого рассказа о том, как устроен ABBYY FineReader (aka «теоретическая часть»), самое время перейти к применению полученных знаний. И да, котиков под катом нет: всё очень серьёзно.
Как пользователю поучаствовать в обработке документа
Чтобы не изобретать велосипед, начну с простой и понятной схемы из Справки (см. рисунок справа).
Теперь, зная список всех операций, посмотрим на примерах – что может пойти не по плану и как с этим бороться.
Хорошо распознаются только хорошие изображения
А что делать, когда изображения есть, но не очень хорошие? Улучшить прямо в FineReader всё что можно, а, если улучшить нельзя, — попытаться получить изображение заново, устранив проблему. Поскольку тема очень обширная, то при должном интересе будет отдельный пост про то, как подружиться с автоматическими и ручными инструментами обработки изображений прямо в FineReader. Пока же ограничусь замечанием, что изображение будет обработано лучше, если оно:
- (после сканирования) не имеет выраженных геометрических искажений — перекоса или заметного изгиба страниц толстой книги у корешка двухстраничного разворота,
- (после фотографирования, в дополнение к предыдущему) не имеет ещё и нелинейных геометрических искажений («подушка», «трапеция»), имеет равномерную фокусировку (а желательно и яркость) по всей площади, не имеет шумов от недостаточной освещённости, не имеет выраженной засветки от вспышки (особенно на глянцевой бумаге).
Этап настройки документа/проекта
Можно и нужно сразу указать язык текста, параметры предобработки изображений, некоторые параметры анализа и распознавания. Вот скриншот одной из вкладок диалога настроек.
Эти и прочие настройки подробно описаны в Справке
Этап анализа
Программа автоматически выделяет области различных типов с точки зрения распознавания. На этом этапе мы можем как самостоятельно разметить области, так и поправить (при необходимости) те, что нашёл модуль Анализа.
Чтобы не писать много лишнего про инструменты работы с областями, сошлюсь на раздел Справки, а здесь объясню, что для чего, «что такое хорошо, что такое плохо» (применительно к областям) и как исправить плохой результат.
Назначение областей разных типов
В пользовательском интерфейсе FineReader доступны области нескольких типов, для них есть разные варианты скрываемой панели свойств (внизу окна «Изображение») и контекстного меню (по щелчку правой кнопкой мыши):
- «Зона распознавания» (по умолчанию серая рамка) — такое название использовано в пользовательском интерфейсе, на мой взгляд правильнее было бы назвать «область для автоматического анализа». Назначение такой области – указать, где на странице вообще нужно искать что-то полезное. Поэтому в результате последующего анализа или анализа+распознавания в пределах каждой «зоны распознавания» может найтись ноль и более областей других типов. Особенно полезны зоны распознавания бывают в шаблонах блоков (подробнее о них в Справке).
Текстовая область – содержит текст одной и более строк, каждая из которых содержит логически связный текст, поэтому выделять две колонки в один блок – очень плохая идея. Может иметь непрямоугольную форму. Бывает нужно задать или поправить после неверного определения автоанализом направление текста, «инверсность» (упрощённо: тёмный текст на светлом фоне — «обычный текст», а светлый текст на тёмном фоне – «инверсный» текст, по умолчанию установлена в «Авто» и почти никогда не требует коррекции).
Эти параметры задаются на блок, так что выделять текст разного направления или разной инверсности в один блок – другая плохая идея.
Табличная область – содержит таблицу, как с видимыми разделителями строк и столбцов, так и невидимыми (частично или везде). Таблица может иметь только прямоугольную форму, каждая из ячеек тоже является прямоугольником, но используя объединение групп ячеек или групп строк, можно передавать весьма сложные конфигурации текста.
В каждой ячейке может быть распознаваемый текст (возможно, пустой) или картинка. Если вы хотите распознавать текст в ячейке, то можно задать ему особые параметры распознавания, а если нет, то стоит указать «картинка во всю ячейку». Кстати, можно выделить сразу прямоугольную группу ячеек таблицы и изменить нужное свойство у всех сразу.
Таблицы — сложный объект для автоматического анализа, особенно при частично или везде невидимых разделителях. Чрезвычайно важно, что вручную исправить расположение и разметку таблицы до первого или повторного распознавания всегда проще, чем исправлять неверную структуру текста уже после распознавания — в FineReader или даже после сохранения, в целевом приложении. Так что в разделе «Практикум» я приведу очень много примеров из реальной жизни исправления ошибок автоматической разметки таблиц.
Важные соображения
- Распознавание и синтез видят только те фрагменты текста, которые оказались выделены в текстовые области или текстовые ячейки таблиц. Если кусок текста не выделен в блоки – распознаваться он не будет.
- Аналогично и с картинками — если часть картинки оказалась вне области или одна целостная картинка оказалась разделена на несколько областей – скорее всего, в результате обработки будут проблемы.
- Языки распознавания в FineReader задаются не для галочки – они влияют на очень многие механизмы, начиная уже с анализа: например, иероглифический (китайский, японский, корейский языки) или арабский текст имеют много особенностей, которые учитываются не всегда, а только при выборе соответствующих языков распознавания.
Особенности взаимодействия близкорасположенных или пересекающихся областей
Следующие правила важны как для правильного обращения с областями в оболочке программы, так и для понимания — что с ними получится в результатах распознавания и сохранения.
- Пересечение текстовых и табличных блоков друг с другом, если есть символы или их части, оказавшиеся в более чем одном блоке – практически всегда ошибка, такие результаты анализа нужно исправлять, тем более что обычно это делается в несколько движений мыши.
Пересечение картиночных областей друг с другом – практически всегда ошибка, хотя и менее критичная для обработки именно текста. Такие случаи тоже желательно исправлять.
Картиночная область на фоне большей текстовой области – законное и нередко востребованное сочетание. Основное применение – обработка так называемых inline-картинок, когда внутри строки (или между строк) встречается фрагмент (пиктограмма, формула или её часть и т.п.), который плохо распознаётся или совсем не распознаётся в используемой в FineReader модели текста.
Текстовая область на фоне «картиночной» области — тоже важный инструмент: на фоне обычных картиночных областей могут находиться подписи к ним, на «фоновых» картиночных областях может располагаться и основной («колоночный») текст документа, а также таблицы.
Маленькие хитрости для облегчения работы с блоками
Описанные соглашения отражены в поведении редактора блоков. Например, если вы рисуете новый или растягиваете имеющийся блок так, что он полностью или почти полностью перекрывает другие блоки — эти другие блоки автоматически удаляются.
Логичность/нелогичность выделения областей
Тут самое время подумать — для каких целей и какого формата документ хочется получить в результате обработки. Вот некоторые соображения, влияющие на количество и характер исправлений разметки блоков в сложных случаях:
Вариант 1: нам нужен только текст (возможно, мы этого не понимаем, но дело обстоит именно так)
Если нужно сохранить документ в PDF с изображениями страниц исходного документа и добавленным «невидимым» распознанным текстом (для его поиска и копирования), то главное – обеспечить разумное выделение текста в текстовые и табличные блоки. Под «разумностью» здесь понимается следующее:
- нет «мусорных» областей, где в качестве текста или таблиц распознаются (мусором) элементы картинок или элементов оформления страницы.
- области логично выделяют строки, не допуская попадания символов в более чем одну область и неоправданного дробления строк на более чем одну область.
- то, что с точки зрения человека является таблицами в оригинале, должно быть выделено в табличные области. Это влияет как на качество распознавания (например, базовые линии строк в разных ячейках могут быть не выровнены по вертикали), так и на удобство поиска и копирования фрагментов текста в выходном документе.
Если отдельные картинки не должны копироваться из выходного PDF-документа – то такие области можно из документа исключить вовсе (не создавать новые и не оставлять найденные автоматикой, как минимум – удалять нелогично найденные картинки, а если не лень – то и все).
Я надеюсь шире и глубже раскрыть тему «разумности» картинок в статье про сохранение документов — если такая будет интересна читателям данного материала.
Вариант 2: нужно всё и сразу
Если документ, включающий не одно лишь текстовое содержимое (в одну или две колонки), предполагается сохранить сразу как электронную книгу в форматах FB2/e-pub или в любой промежуточный редактируемый формат (Вордовый или HTML) для дальнейшего редактирования и производства электронной книги, то осмысленное выделение таблиц и картинок становится особенно важно.
Среди прочего нужно определиться с тем, что делать с группами рядом расположенных картинок, и что делать с подписями к картинкам, как рядом стоящими, так и накладывающимися на картинки. Подробнее разберём эту тему в «Практикуме», на реальных примерах.
Источник



