- Как настроить синтезатор речи Google на Android
- Изменение скорости речи и высоты тона
- Изменение скорости речи
- Изменение высоты тона
- Выбор голоса синтезатора речи
- Переключение языков
- Сторонние движки синтезатора речи
- Не могу настроить синтез речи
- Настройка параметров речи в Windows 7
- Нейросетевой синтез речи своими руками
- Синтез речи
- Лингвистика
- Просодика
- Фонетика
- Акустика
- Реализации
- Данные для обучения
- Начнем
- Текст
Как настроить синтезатор речи Google на Android

В то время как Google фокусируется на Помощнике, владельцы Android не должны забывать о функции синтеза речи (TTS). Она преобразует текст из Ваших приложений для Android, но Вам может потребоваться изменить его, чтобы речь звучала так, как Вы этого хотите.
Изменение синтеза речи легко сделать из меню настроек специальных возможностей Android. Вы можете изменить скорость и тон выбранного Вами голоса, а также используемый голосовой движок.
Синтезатор речи Google — это голосовой движок по умолчанию, который предварительно установлен на большинстве устройств Android. Если на Вашем Android-устройстве он не установлен, Вы можете загрузить приложение Синтезатор речи Google из Google Play Store.
Изменение скорости речи и высоты тона
Android будет использовать настройки по умолчанию для Синтезатора речи Google, но Вам может потребоваться изменить скорость и высоту голоса, чтобы Вам было легче его понять.
Изменение скорости речи и высоты тона TTS требует, чтобы Вы попали в меню настроек специальных возможностей Google. Шаги для этого могут незначительно отличаться, в зависимости от Вашей версии Android и производителя Вашего устройства. В данной статье используется устройство Honor 8 lite, работающее на Android 8.0.
Чтобы открыть меню специальных возможностей Android, перейдите в меню «Настройки» Android. Это можно сделать, проведя пальцем вниз по экрану для доступа к панели уведомлений и нажав значок шестеренки в правом верхнем углу, или запустив приложение «Настройки» в своем списке приложений.

В меню «Настройки» нажмите «Управление», а оттуда «Специальные возможности».

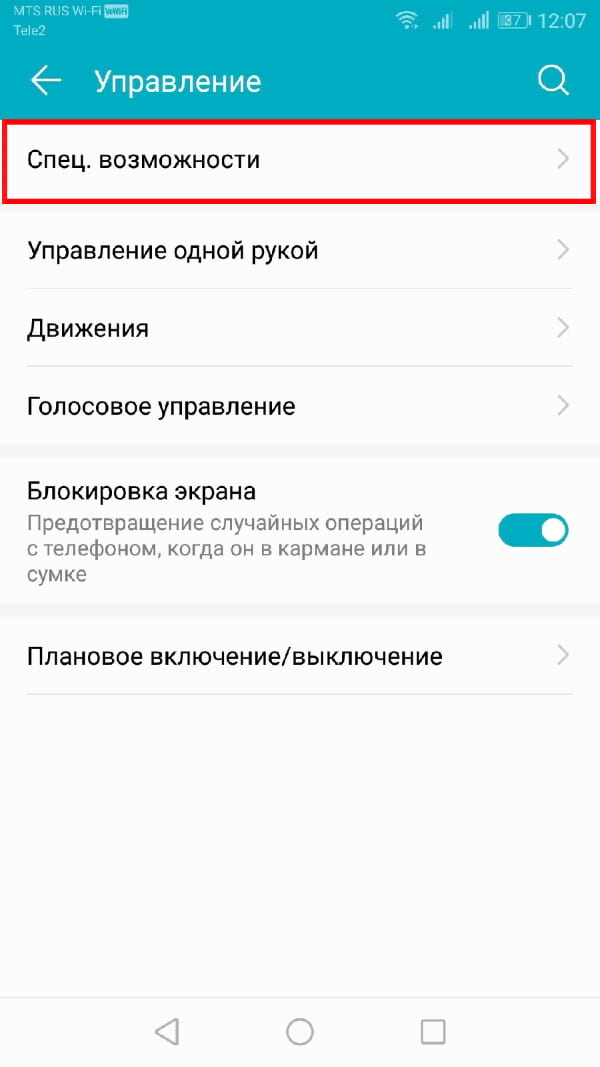
Выберите «Синтез речи».

Отсюда Вы сможете изменить настройки преобразования текста в речь.
Изменение скорости речи
Скорость речи — это скорость, с которой будет говорить синтезатор речи. Если Ваш TTS движок слишком быстрый (или слишком медленный), речь может звучать искаженно или плохо для понимания.
Если Вы выполнили вышеуказанные действия, Вы должны увидеть слайдер под заголовком «Скорость речи» в меню «Синтез речи». Проведите пальцем вправо или влево, чтобы повысить или понизить скорость.
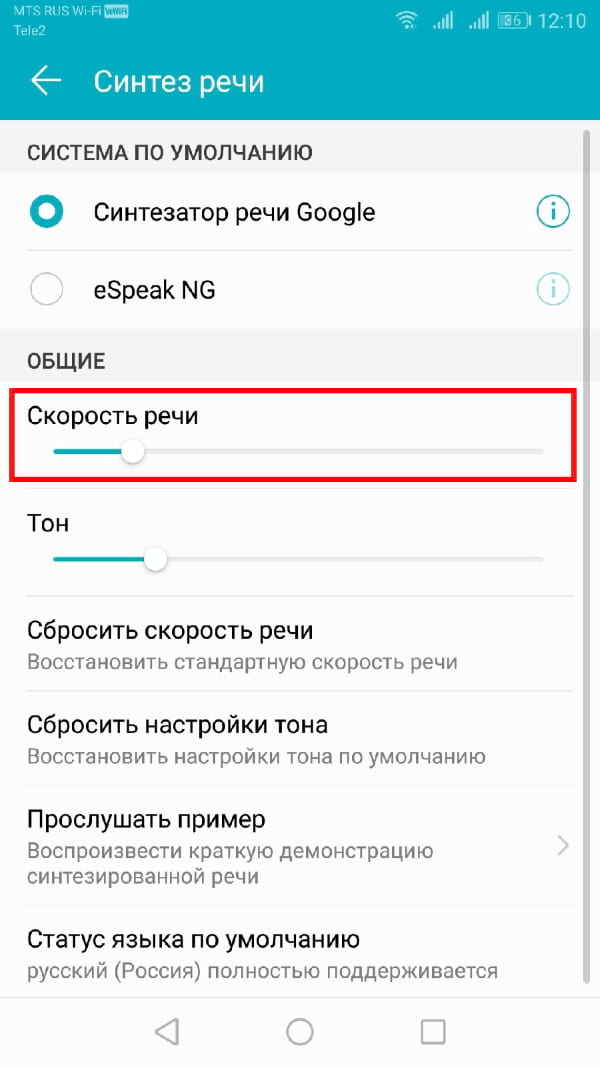
Нажмите кнопку «Прослушать пример», чтобы проверить новый уровень речи.

Изменение высоты тона
Если Вы чувствуете, что тон преобразованного текста в речь слишком высок (или низок), Вы можете изменить это, следуя тому же процессу, что и при изменении скорости речи.
Как и выше, в меню настроек «Синтез речи» отрегулируйте ползунок «Тон» в соответствии с желаемой высотой тона.
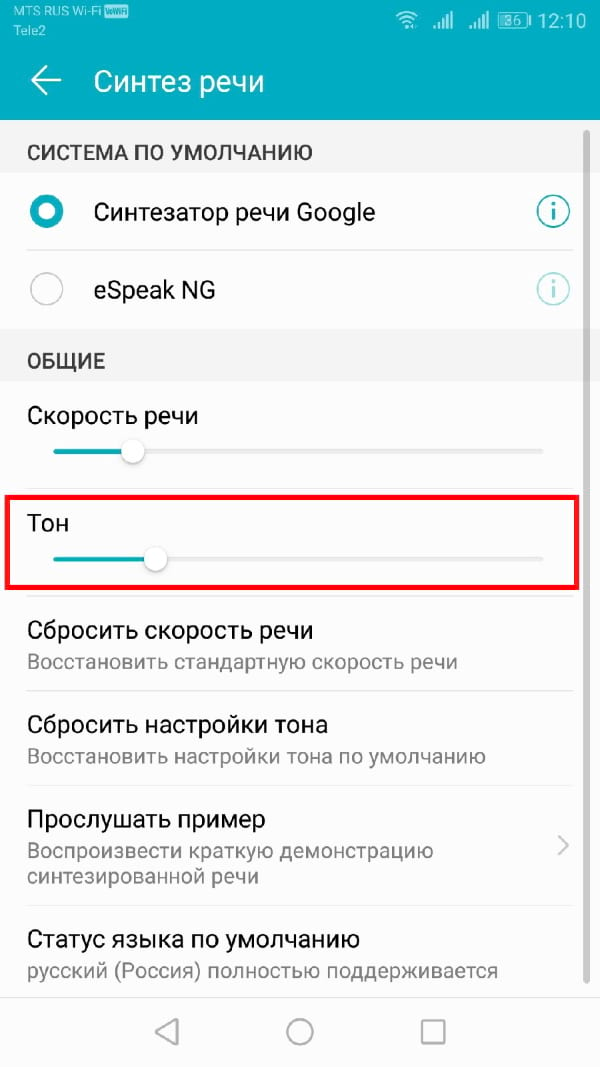
Когда Вы будете готовы, нажмите «Прослушать пример», чтобы попробовать новый вариант.
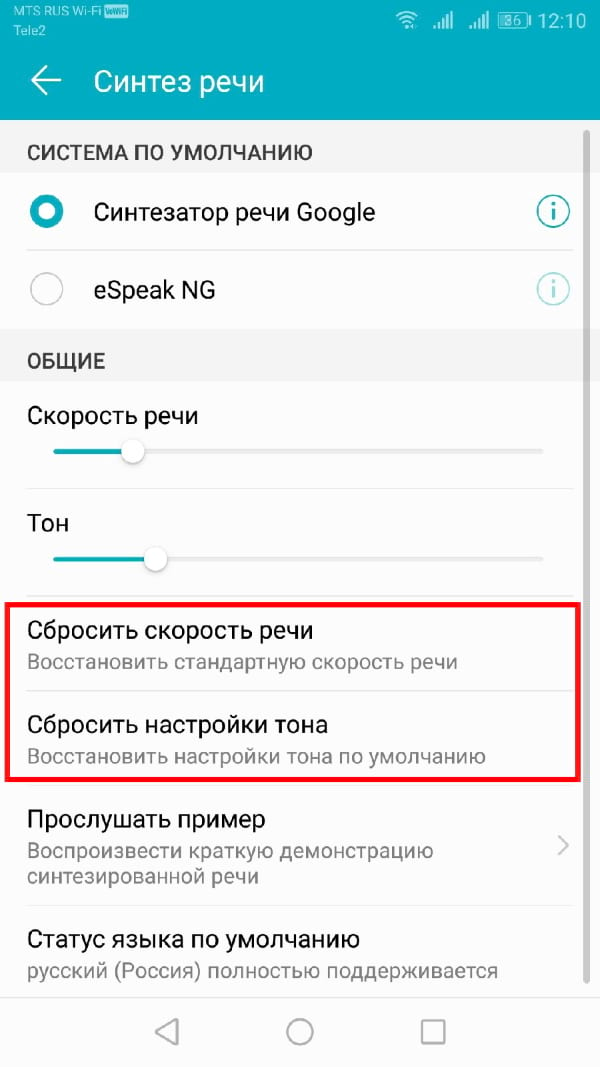
Продолжайте этот процесс, пока Вы не будете довольны настройками скорости речи и высоты тона, или нажмите «Сбросить скорость речи» и/или «Сбросить настройки тона», чтобы вернуться к настройкам TTS по умолчанию.
Выбор голоса синтезатора речи
Вы можете не только изменить тон и скорость своего речевого движка TTS, но и изменить голос. Некоторые языковые пакеты, включенные в стандартный движок Синтезатор речи Google, имеют разные голоса, которые звучат как мужской, так и женский.
Если Вы используете Синтезатор речи Google, нажмите кнопку «i» рядом названием.

В меню «Настройки» нажмите «Установка голосовых данных».
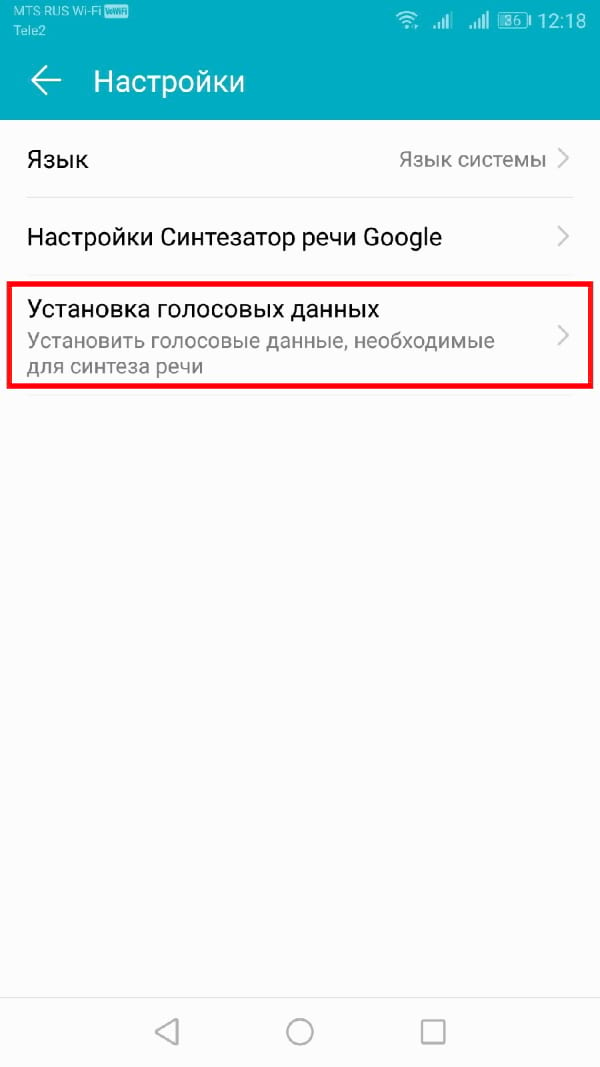
Нажмите на выбранный Вами язык.
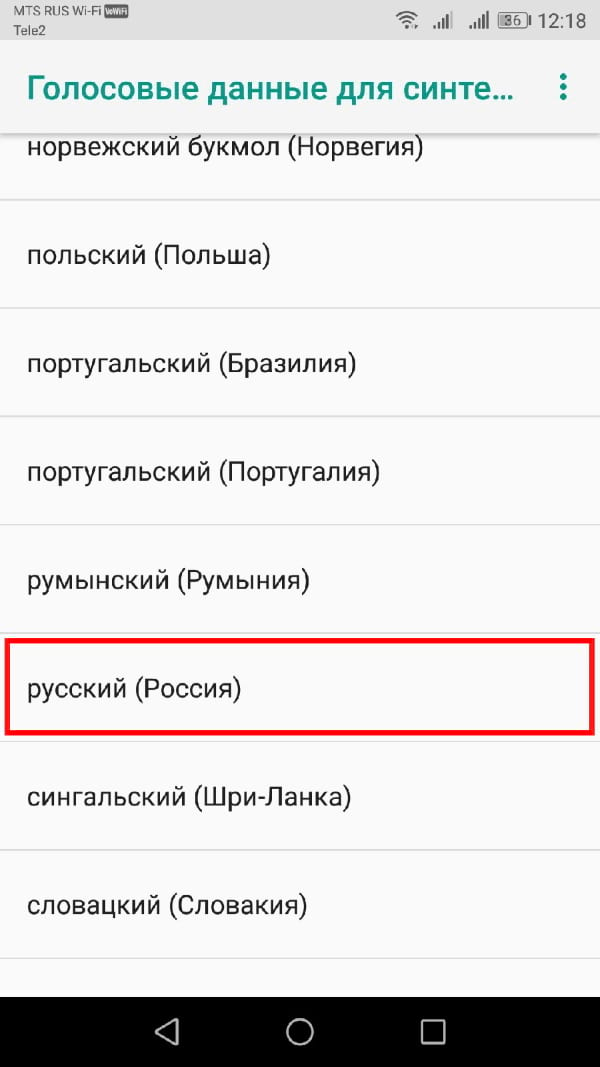
Вы увидите различные голоса, перечисленные и пронумерованные, начиная с «Голоса I». Нажмите на каждый, чтобы услышать, как он звучит. Вы должны убедиться, что на Вашем устройстве включен звук.
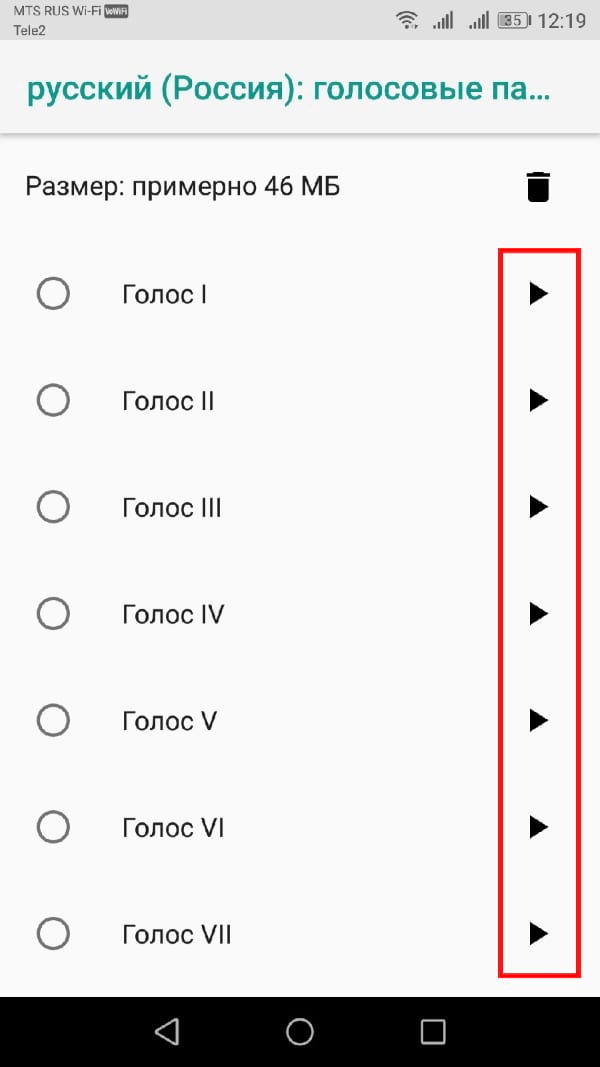
Выберите голос, который Вас устраивает в качестве Вашего окончательного выбора.
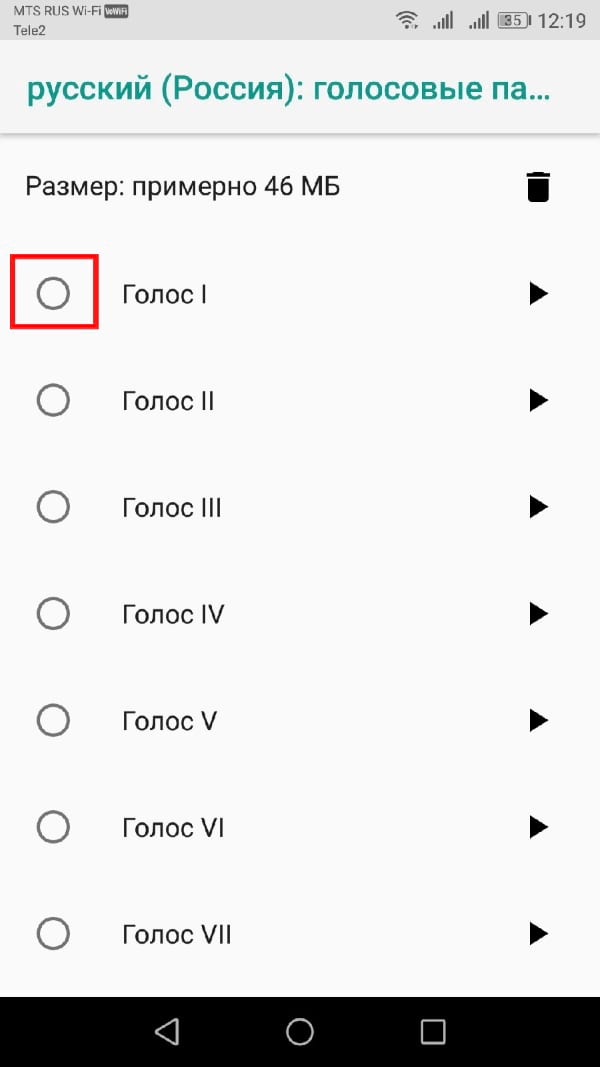
Ваш выбор будет автоматически сохранен, хотя, если Вы выбрали другой язык по умолчанию для Вашего устройства, Вам также придется изменить его.
Переключение языков
Если Вам нужно переключить язык, Вы можете легко сделать это из меню настроек Синтеза речи. Возможно, Вы захотите сделать это, если Вы выбрали язык в Вашем движке TTS, отличный от языка Вашей системы по умолчанию.
Вы должны увидеть опцию «Язык». Нажмите, чтобы открыть меню.
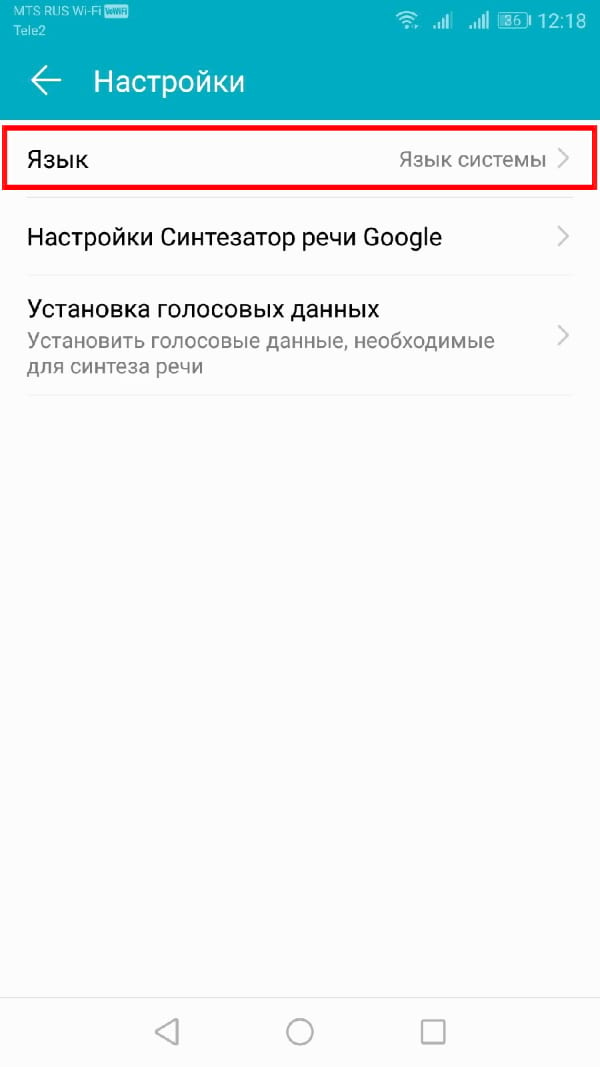
Выберите свой язык из списка, нажав на него.
Сторонние движки синтезатора речи
Если Синтезатор речи Google Вам не подходит, Вы можете установить альтернативные варианты.
Их можно установить из Google Play Store или установить вручную. Примеры движков TTS, которые Вы можете установить, включают Acapela и eSpeak TTS, хотя доступны и другие.
Источник
Не могу настроить синтез речи

Здравствуйте, уважаемые пользователи!
В данной теме мы размещаем информацию для тех пользователей, у которых возникли трудности с озвучкой в нашем приложении на устройствах под управлением операционной системы Android
**При этом у пользователей на экране устройства выводится сообщение «Для озвучивания необходимо установить компоненты английского языка English (United States)».**
Для настройки озвучки на Android-устройствах мы рекомендуем вам выполнить следующие действия:
1. Зайти в раздел «Настройки» («Settings») своего устройства.
2. В меню настроек выбрать пункт «Язык и ввод» («Language & Input») или «Язык и клавиатура» («Language & Keyboard»)
3. Далее в меню настроек языка найти раздел «Голосовой ввод» («Speech»). В данном разделе выбрать пункт «Синтез речи» («Text-to-speech output»).
**Примечание: если раздел «Голосовой ввод» («Speech») пуст, необходимо перейти к пункту 5.**
4. В меню настроек «Синтез речи» в разделе «Система по умолчанию» («Default system») выбрать пункт «Синтезатор речи Google».
**Примечание: в случае, если в меню настроек «Синтез речи» отсутствует пункт «Синтезатор речи Google», необходимо перейти к пункту 5.**
5. В магазине Google Play необходимо найти и скачать приложение «Синтезатор речи Google». Это приложение бесплатное, его разработчиком является компания Google.
6. После установки «Синтезатора речи Google» необходимо проделать шаги 1-4.
После выполнения данных действий озвучка должна заработать.
В случае, если у вас возникнут вопросы касательно данной инструкции или проблемы с настройкой, то просим Вас связаться с нами по эл. почте itadmin@noxx.ru или в данной теме для обсуждений, чтобы мы оперативно смогли помочь Вам в решении вопросов по настройке озвучки.
C уважением,
команда разработчиков «Партнера»!
Источник
Настройка параметров речи в Windows 7
Поддержка Windows 7 закончилась 14 января 2020 г.
Чтобы продолжить получать обновления системы безопасности от Майкрософт, мы рекомендуем перейти на Windows 10.
С помощью диалогового окна «Свойства речи» вы можете настраивать параметры распознавания речи Windows и преобразования текста в речь.
Откройте «Распознавание речи», нажав  «Пуск», на панели управления,выберите «Удобство доступа» и «Распознавание речи».
«Пуск», на панели управления,выберите «Удобство доступа» и «Распознавание речи».
На левой панели нажмите Дополнительные параметры речи.
В следующей таблице описаны параметры на вкладке «Распознавание речи».
Выводит список доступных систем распознавания речи. Выберите нужную систему.
Распознавание речи доступно только на английском, французском, испанском, немецком, японском, упрощенном китайском и традиционном китайском.
Показывает дополнительные свойства системы. Набор свойств зависит от типа системы, и не у всех систем есть дополнительные свойства.
Профили распознавания речи
Выводит список доступных профилей пользователей. Выберите профиль в списке, чтобы отметить его как активный.
Добавляет профиль пользователя. Запускается мастер добавления профиля, где можно настроить профиль и калибровать микрофон и динамики. Автоматически запускается мастер настройки микрофона.
Удаляет выбранный профиль. Удаляемый профиль не должен использоваться другими программами.
Запускает мастер обучения распознаванию речи. Этот мастер поможет повысить точность распознавания, изучив вашу манеру разговора и посторонние звуки.
Запускать распознавание речи при запуске компьютера
Запускает программу распознавания речи при включении компьютера.
Просмотреть документы и почту для повышения точности
Позволяет программе распознавания речи проверять документы и сообщения электронной почты на компьютере, запоминая часто используемые слова и фразы. Это помогает повысить точность распознавания.
Включить активацию функции речи
Запускает программу распознавания речи в спящем режиме и позволяет переводить ее в спящий режим с помощью команды «Перестать слушать».
Число пробелов, вставляемых между предложениями
Задает число пробелов, вставляемых после знаков препинания, обозначающих конец предложения, при диктовке текста с помощью распознавания речи.
Указывает уровень звука микрофона.
Открывает диалоговое окно «Звук». Вы можете настроить параметры устройств записи звука.
Позволяет задать предпочитаемое аудиоустройство, например входное устройство для распознавания речи. Эта кнопка будет активна, только если установлено по крайней мере одно аудиоустройство.
Запускает мастер настройки микрофона. Это помогает калибровать входные аудиоустройства и уровни динамиков.
В следующей таблице описаны параметры преобразования текста в речь на вкладке «Текст в речь».
Выводит список доступных голосов. Выберите голос, чтобы активировать его. После выбора голоса обработчик преобразования текста в речь произнесет текст для проверки этого голоса.
Показывает дополнительные сведения об обработчике преобразования текста в речь или его параметры. Отображаемые сведения зависят от типа обработчика, и не у всех обработчиков есть дополнительные свойства.
Использовать следующий текст для пробы голоса
Отображает текст, произносимый обработчиком преобразования текста в речь. Вы можете временно изменить текст, но он всегда возвращается к исходному.
Проговаривает текст в поле Использовать следующий текст для пробы голоса с помощью выбранного голоса. Каждое слово выделяется, когда обработчик проговаривает его. Во время пробы голоса текст кнопки изменяется на «Остановить», что позволяет завершить проверку. После завершения (или остановки) проверки кнопка «Остановить» снова изменится на кнопку «Проба голоса».
Регулирует скорость голоса для преобразования текста в речь.
Открывает диалоговое окно «Звук». Вы можете настроить параметры устройств воспроизведения звука.
Нажмите эту кнопку, чтобы задать предпочитаемое аудиоустройство для преобразования текста в речь. Эта кнопка будет активна, только если установлено по крайней мере одно аудиоустройство.
Источник
Нейросетевой синтез речи своими руками
Синтез речи на сегодняшний день применяется в самых разных областях. Это и голосовые ассистенты, и IVR-системы, и умные дома, и еще много чего. Сама по себе задача, на мой вкус, очень наглядная и понятная: написанный текст должен произноситься так, как это бы сделал человек.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Синтез речи
Чтобы построить систему синтеза речи, нужна целая команда специалистов из разных областей. По каждой из них существует целая масса алгоритмов и подходов. Написаны докторские диссертации и толстые книжки с описанием фундаментальных подходов. Давайте для начала поверхностно разберемся с каждой их них.
Лингвистика
Просодика
Фонетика
Акустика
- Подбор звуковых элементов. Системы синтеза оперируют так называемыми аллофонами — реализациями фонемы, зависящими от окружения. Записи из обучающих данных нарезаются на кусочки по фонемной разметке, которые образуют аллофонную базу. Каждый аллофон характеризуется набором параметров, таких как контекст (фонемы соседи), высота основного тона, длительность и прочие. Сам процесс синтеза представляет собой подбор правильной последовательности аллофонов, наиболее подходящих в текущих условиях.
- Модификация и звуковые эффекты. Для получившихся записей иногда нужна постобработка, какие-то специальные фильтры, делающие синтезируемую речь чуть ближе к человеческой или исправляющие какие-то дефекты.
Если вдруг вам показалось, что все это можно упростить, прикинуть в голове или быстро подобрать какие-то эвристики для отдельных модулей, то просто представьте, что вам нужно сделать синтез на хинди. Если вы не владеете языком, то вам даже не удастся оценить качество вашего синтеза, не привлекая кого-то, кто владел бы языком на нужном уровне. Мой родной язык русский, и я слышу, когда синтез ошибается в ударениях или говорит не с той интонацией. Но в тоже время, весь синтезированный английский для меня звучит примерно одинаково, не говоря уже о более экзотических языках.
Реализации
Мы попытаемся найти End-2-End (E2E) реализацию синтеза, которая бы взяла на себя все сложности, связанные с тонкостями языка. Другими словами, мы хотим построить систему, основанную на нейронных сетях, которая бы на вход принимала текст, а на выходе давала бы синтезированную речь. Можно ли обучить такую сеть, которая позволила бы заменить целую команду специалистов из узких областей на команду (возможно даже из одного человека), специализирующуюся на машинном обучении?
На запрос end2end tts Google выдает целую массу результатов. Во главе — реализация Tacotron от самого Google. Самым простым мне показалось идти от конкретных людей на Github, которые занимаются исследованиям в этой области и выкладывают свои реализации различных архитектур.
Я бы выделил троих:
- Kyubyong Park
- Keith Ito
- Ryuichi Yamamoto
Загляните к ним в репозитории, там целый кладезь информации. Архитектур и подходов к задаче E2E-синтеза довольно много. Среди основных:
- Tacotron (версии 1, 2).
- DeepVoice (версии 1, 2, 3).
- Char2Wav.
- DCTTS.
- WaveNet.
Нам нужно выбрать одну. Я выбрал Deep Convolutional Text-To-Speech (DCTTS) от Kyubyong Park в качестве основы для будущих экспериментов. Оригинальную статью можно посмотреть по ссылке. Давайте поподробнее рассмотрим реализацию.
Автор выложил результаты работы синтеза по трем различным базам и на разных стадиях обучения. На мой вкус, как не носителя языка, они звучат весьма прилично. Последняя из баз на английском языке (Kate Winslet’s Audiobook) содержит всего 5 часов речи, что для меня тоже является большим преимуществом, так как моя база содержит примерно сопоставимое количество данных.
Через некоторое время после того, как я обучил свою систему, в репозитории появилась информация о том, что автор успешно обучил модель для корейского языка. Это тоже довольно важно, так как языки могут сильно разниться и робастность по отношению к языку — это приятное дополнение. Можно ожидать, что в процессе обучения не потребуется особого подхода к каждому набору обучающих данных: языку, голосу или еще каким-то характеристикам.
Еще один важный момент для такого рода систем — это время обучения. Tacotron на том железе, которое у меня есть, по моим оценкам учился бы порядка 2 недель. Для прототипирования на начальном уровне мне показалось это слишком ресурсоемким. Педали, конечно, крутить не пришлось бы, но на создание какого-то базового прототипа потребовалось бы очень много календарного времени. DCTTS в финальном варианте учится за пару дней.
У каждого исследователя есть набор инструментов, которыми он пользуется в своей работе. Каждый подбирает их себе по вкусу. Я очень люблю PyTorch. К сожалению, на нем реализации DCTTS я не нашел, и пришлось использовать TensorFlow. Возможно в какой-то момент выложу свою реализацию на PyTorch.
Данные для обучения
Хорошая база для реализации синтеза — это основной залог успеха. К подготовке нового голоса подходят очень основательно. Профессиональный диктор произносит заранее подготовленные фразы в течение многих часов. Для каждого произнесения нужно выдержать все паузы, говорить без рывков и замедлений, воспроизвести правильный контур основного тона и все это в купе с правильной интонацией. Кроме всего прочего, не все голоса одинаково приятно звучат.
У меня на руках была база порядка 8 часов, записанная профессиональным диктором. Сейчас мы с коллегами обсуждаем возможность выложить этот голос в свободный доступ для некоммерческого использования. Если все получится, то дистрибутив с голосом помимо самих записей будет включать в себя точные текстовки для каждой из них.
Начнем
Мы хотим создать сеть, которая на вход принимала бы текст, а на выходе давала бы синтезированный звук. Обилие реализаций показывает, что это возможно, но есть конечно и ряд оговорок.
Основные параметры системы обычно называют гиперпараметрами и выносят в отдельный файл, который называется соответствующим образом: hparams.py или hyperparams.py, как в нашем случае. В гиперпараметры выносится все, что можно покрутить, не трогая основной код. Начиная от директорий для логов, заканчивая размерами скрытых слоев. После этого гиперпараметры в коде используются примерно вот так:
Далее по тексту все переменные имеющие префикс hp. берутся именно из файла гиперпараметров. Подразумевается, что эти параметры не меняются в процессе обучения, поэтому будьте осторожны перезапуская что-то с новыми параметрами.
Текст
Для обработки текста обычно используются так называемый embedding-слой, который ставится самым первым. Суть его простая — это просто табличка, которая каждому символу из алфавита ставит в соответствие некий вектор признаков. В процессе обучения мы подбираем оптимальные значения для этих векторов, а когда синтезируем по готовой модели, просто берем значения из этой самой таблички. Такой подход применяется в уже довольно широко известных Word2Vec, где строится векторное представление для слов.
Для примера возьмем простой алфавит:
В процессе обучения мы выяснили, что оптимальные значения каждого их символов вот такие:
Тогда для строчки aabbcc после прохождения embedding-слоя мы получим следующую матрицу:
Эта матрица дальше подается на другие слои, которые уже не оперируют понятием символ.
В этот момент мы видим первое ограничение, которое у нас появляется: набор символов, который мы можем отправлять на синтез, ограничен. Для каждого символа должно быть какое-то ненулевое количество примеров в обучающих данных, лучше с разным контекстом. Это значит, что нам нужно быть осторожными в выборе алфавита.
В своих экспериментах я остановился на варианте:
Это алфавит русского языка, дефис, пробел и обозначение конца строки. Тут есть несколько важных моментов и допущений:
- Я не добавлял в алфавит знаки препинания. С одной стороны, мы действительно их не произносим. С другой, по знакам препинания мы делим фразу на части (синтагмы), разделяя их паузами. Как система произнесет казнить нельзя помиловать?
- В алфавите нет цифр. Мы ожидаем, что они будут развернуты в числительные перед подачей на синтез, то есть нормализованы. Вообще все E2E-архитектуры, которые я видел, требуют именно нормализованный текст.
- В алфавите нет латинских символов. Английский система уметь произносить не будет. Можно попробовать транслитерацию и получить сильный русский акцент — пресловутый лет ми спик фром май харт.
- В алфавите есть буква ё. В данных, на который я обучал систему, она стояла там, где нужно, и я решил этот расклад не менять. Однако, в тот момент, когда я оценивал получившиеся результаты, выяснилось, что теперь перед подачей на синтез эту букву тоже нужно ставить правильно, иначе система произносит именно е, а не ё.
В будущих версиях можно уделить каждому из пунктов более пристальное внимание, а пока оставим в таком немного упрощенном виде.
Почти все системы оперируют не самим сигналом, а разного рода спектрами полученными на окнах с определенным шагом. Я не буду вдаваться в подробности, по этой теме довольно много разного рода литературы. Сосредоточимся на реализации и использованию. В реализации DCTTS используются два вида спектров: амплитудный спектр и мел-спектр.
Считаются они следующим образом (код из этого листинга и всех последующих взят из реализации DCTTS, но видоизменен для наглядности):
Для вычислений почти во всех проектах E2E-синтеза используется библиотека LibROSA (https://librosa.github.io/librosa/). Она содержит много полезного, рекомендую заглянуть в документацию и посмотреть, что в ней есть.
Теперь давайте посмотрим как амплитудный спектр (magnitude spectrum) выглядит на одном из файлов из базы, которую я использовал:

Такой вариант представления оконных спекторов называется спектрограммой. На оси абсцисс располагается время в секундах, на оси ординат — частота в герцах. Цветом выделяется амплитуда спектра. Чем точка ярче, тем значение амплитуды больше.
Мел-спектр — это амплитудный спектр, но взятый на мел-шкале с определенным шагом и окном. Количество шагов мы задаем заранее, в большинстве реализаций для синтеза используется значение 80 (задается параметром hp.n_mels). Переход к мел-спектру позволяет сильно сократить количество данных, но этом сохранить важные для речевого сигнала характеристики. Мел-спектрограмма для того же файла выглядит следующим образом:
Обратите внимание на прореживание мел-спектров во времени на последней строке листинга. Мы берем только каждый 4 вектор (hp.r == 4), соответственно уменьшая тем самым частоту дискретизации. Синтез речи сводится к предсказанию мел-спектров по последовательности символов. Идея простая: чем меньше сети приходится предсказывать, тем лучше она будет справляться.
Хорошо, мы можем получить спектрограмму по звуку, но послушать мы ее не можем. Соответственно нам нужно уметь восстанавливать сигнал обратно. Для этих целей в системах часто используется алгоритм Гриффина-Лима и его более современные интерпретации (к примеру, RTISILA, ссылка). Алгоритм позволяет восстановить сигнал по его амплитудным спектрам. Реализация, которую использовал я:
А сигнал по амплитудной спектрограмме можно восстановить вот так (шаги, обратные получению спектра):
Давайте попробуем получить амплитудный спектр, восстановить его обратно, а затем послушать.
Источник



