- Notepad++: поиск и замена в файлах
- Поиск и изменение текста с переносом строки Enter в Нотепад++
- Массовая замена сразу во всех файлах папки
- Удаление кусков текста
- Заменить все одинаковые слова
- Удалить замыкающие пробелы или пустые строки
- Многострадальный notepad: ошибка, которую не исправляют уже 13 лет
- Как при помощи Notepad++ заменить не все найденные слова?
- Notepad++ замена символов, перенос на новую строку
- Решение
- Справочная информация. Наборы выражений Notepad++
Notepad++: поиск и замена в файлах
Поиск и изменение текста с переносом строки Enter в Нотепад++
Для того, чтобы найти либо поменять одну или несколько строк текста, вовсе необязательно включать режим «Расширенный (\r, \n, \t, \х. \0)».
- Выделить искомый участок,
- выбрать в верхнем меню «Поиск» — «Замена»,
- в появляющемся окне поле «Найти» будет заполнено,

- написать или вставить откуда-нибудь ранее скопированный текст, на который нужно будет выполнить замену,
- скопировать текст, на который нужно будет выполнить замену, уже из интерфейса Notepad++,
- установить курсор в начало первой строки, чтобы начать поиск с неё, а не с середины документа,
- вставить сохранённый текст в поле «Заменить на» (табуляция, пробелы, переносы строк будут учтены, хоть и не будут видны),
- нажать одну из кнопок
- «Заменить» — замена одного фрагмента в рамках текущего документа,
- «Заменить все» — замена всех фрагментов в рамках текущего документа,
- «Заменить все во всех Открытых Документах» — замена всех фрагментов во всех открытых документах.
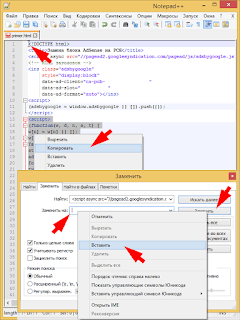
Массовая замена сразу во всех файлах папки
- Открыть вкладку «Найти в файлах»,
- фильтр *.* означает, что осуществляется поиск всех вхождений,
- выбрать папку, в которой лежат файлы, требующие изменения,
- установить галку «Во всех подпапках»,если нужно редактировать искомый фрагмент и внутри вложенных папок.

Вполне удобно, когда один рекламный блок нужно сменить на другой.
Удаление кусков текста
Поле «Заменить на» отставить пустым.
Заменить все одинаковые слова
Слова в русском языке склоняются и спрягаются, начинаются с заглавной и строчной буквы, могут быть окружены знаками препинания, неучтённым в Нотпед++.
- Без галки «Только целые слова»
- С галкой «Только целые слова»
Удалить замыкающие пробелы или пустые строки
Выбрать в верхнем меню:
- «Правка» — «Операция со Строками» — «Удалить Пустые Строки»
- «Правка» — «Операция со Строками» — «Удалить Пустые Строки (Содер. символы Пробела)»
- «Правка» — «Операция с Пробелами» — «Убрать замыкающие пробелы»
Источник
Многострадальный notepad: ошибка, которую не исправляют уже 13 лет

В стандартном блокноте для всех версий Windows, начиная примерно с 2001 года, имеется ошибка, про которую практически все знают, но никто не собирается её исправлять. И это понятно, ведь это не критическая уязвимость, ничьей безопасности она не угрожает. Да и пользуется ли кто блокнотом вообще?
Тем не менее, сам факт довольно странный, поэтому мы попробуем найти эту ошибку в коде 64-битного и 32-битного notepad.exe от windows 7, исправим её, и выясним наконец, почему же она возникла. Заключается ошибка в следующем:
Если в блокноте включена опция «перенос по словам» (word wrap), то после сохранения файла начинаются всевозможные глюки: строки начинают разъезжаться, курсор улетает, текст вводится не туда, куда вы ожидаете, и так далее.
Для начала попытаемся поточнее выяснить, что же происходит. Откроем или введём какой-нибудь текст с длинными строками, чтобы они переносились. Сохраним файл. Если теперь попытаться его редактировать, например, добавив слово «синими», строки будут переноситься неправильно, ломая форматирование:
Если уменьшать окно блокнота, строки разрезаются (это видно на заглавной картинке), а при растягивании остаются на месте, не заполняя увеличивающееся окно. Как будто в каждой строке появился жесткий «перевод строки» в том месте, где она заканчивалась в момент сохранения. Видимо текст каким-то образом портится в памяти:
Если же теперь снова сохранить файл, станет ещё хуже. Все строки переформатируются, но окно не обновится. Поэтому курсор может переместиться в другое место, а если начать вводить текст, окажется, что вы вводите его не в то место, где находится курсор, а совсем в другое. Программисты, которые писали notepad, рассуждали логично: при сохранении файла ничего в окне не должно поменяться, поэтому и нет смысла его обновлять. Но в нашем случае с учётом этой ошибки весь текст меняется. Воспроизвести ситуацию может каждый пользователь windows, потому что последняя версия, где этой ошибки не было — Windows’98, и вряд ли у кого она ещё осталась.
Итак, по всей видимости, при сохранении файла что-то идёт не так и текст портится. Как найти это место в коде? Откроем notepad.exe в каком-нибудь отладчике. Как известно, в 64-битной системе для совместимости имеется два блокнота: 32- и 64-битный, надо не перепутать их.
Введём текст, на котором легко будет увидеть, как он портится при переносе строк. Наберём в одну строку «first text line second text line», а затем уменьшим окно так, чтобы она разрезалась посередине.
Резонно будет предположить, что запись делается с помощью функции WriteFile. Оказывается, она вызывается в коде целых 6 раз. Недолго думая, поставим точки останова на все 6 вызовов. Запускаем блокнот и нажимаем «сохранить». Выполнение останавливается здесь:
Посмотрим все регистры, где содержатся параметры вызова. В rcx у нас 104, это непонятно что. A rdx = 002D45E0, это похоже на адрес в памяти. Посмотрим, что там.
Отлично. Отсюда у нас идёт запись. Попробуем выполнить код дальше, чтобы посмотреть, где он портится. Однако почти сразу данные затираются, а это значит, что это всего лишь временный буфер, а сам текст хранится где-то ещё. Посмотрим выше по программе.
Ага, перед сохранением текст видимо преобразовывается из многобайтовой кодировки в однобайтовую. Точно так же, как в прошлый раз, посмотрим параметры. rax = 002D45E0, здесь у нас пока нули. Это как раз то место, куда попадёт результат. esi = 20, это длина текста. есх = 4еЗ, без комментариев. edx = 400, то же самое. А вот r8 = 002D6780:
Снова продолжим выполнение, наблюдая за содержимым этого участка памяти. Через несколько десятков команд мы выходим из подпрограммы, выполняются какие-то переходы, вызовы, но мы, не обращая на это внимания, продолжаем давить на «step over», выполняя код по шагам, и следя только за окном с текстом. И вот в какой-то момент он изменяется. Как видим, между 1 и 2 строкой появились коды 0d, 0d, 0a:
Как обычно бывает, мы проскочили нужную команду, постоянно давя на кнопку, поэтому придётся повторить всё ещё раз, запомнив, где примерно это произошло. Теперь по мере приближения к нужному месту в коде, замедляемся, и точно определяем, что текст испортился вот на этом вызове:
Можно попробовать, что будет, если не делать этот вызов. Снова доходим до этого места, и прямо тут, в отладке, изменяем RIP (регистр, где хранится адрес выполняемого в данный момент кода) на 00000000FFA38EE1, как будто мы пропустили этот call, который нам всё испортил. Удивительно, всё работает, текст не ломается!
Тут надо сказать, что в таких случаях обычно не разбираются, что это за подпрограмма, что она делает и зачем, а просто выкидывают её из EXE-файла. Это можно сделать разными способами, например, забить её всю NOP’ами, или изменить условный переход по равенству «je», который так кстати имеется сразу перед ней, на безусловный «jmp».
Но нам сейчас не столько нужно исправить эту ошибку, как интересно выяснить, откуда же она вообще взялась. Поэтому заходим внутрь и смотрим:
Вот такая замечательная маленькая подпрограмма. Проходим её по шагам. Сначала сравниваются какие-то две переменные с нулём, в результате первый вызов неизвестно чего не делается, а делаются подряд для вызова SendMessage. То есть, всё, что происходит, это посылается два каких-то виндовых сообщения, причём текст портится сразу же после первого (выделен зеленым). Невооруженным глазом видно, что в EDX передаются их коды (выделен красным). Поищем код 0C8h.
Это оказывается сообщение EM_FMTLINES. Довольно похоже, посылаем сообщения для форматирования строк, вот и доформатировались. Пришло время почитать документацию. MSDN сообщает нам следующее:
Это сообщение определяет включение «мягких» переводов строки в многострочный элемент редактирования. «Мягкий» перевод строки представляет из себя два символа [CR] и один [LF] и вставляется в строку там, где она разрезается при переносе по словам.
Параметр wParam: true — вставить символы, false — удалить их.
Сообщение влияет только на буфер, возвращаемый сообщениями EM_GETHANDLE и WM_GETTEXT, и не влияет на текст, отображаемый в элементе редактирования. Также оно не влияет на «жёсткие» переводы строки, которые состоят из одного [CR] и одного [LF].
Кроме того, мы узнаём, что данное сообщение было введено не позднее чем в Windows 95. Ну вот всё и стало понятно. В 95 году предполагалось, что оно не влияет, а сейчас видим, что влияет, да ещё как. Немного поизучав код, находим несколько аналогичных вызовов, и нашему мысленному взору предстаёт следующая картина:
Давным-давно, в первой половине 90-х годов, программисты Microsoft писали блокнот для Windows 95. Чтобы реализовать замечательную функцию переноса строк, они придумали посылать окну (или его элементу) сообщение, чтобы оно само переформатировало себя, навставляв специальных символов. Чтобы эти символы отличить от нормального перевода строки, они придумали последовательность 0d, 0d, 0а. Чтобы она не попадала в файл, перед сохранением все такие коды удалялись, а после сохранения добавлялись обратно.
Позже, когда делали windows ХР, элемент стал сам всё переносить как надо, и ему уже не нужно было это сообщение. Однако, никто уже не помнил, зачем оно было нужно, и поэтому решили на всякий случай оставить как было. Тем более, вроде бы всё работало, а проблем после сохранения никто не заметил. С тех пор этот код так и остался, дойдя до самых последних версий Windows 7 и 8. Десятку я не ставил, но скорее всего, там он тоже есть.
Перейдем теперь к исправлению ошибки. После сообщения 0С8h посылается ещё OB1h, а это EM_SETSEL — установка выделения. Похоже, выкидывать эту подпрограмму целиком всё же неправильно, да ещё там есть какой-то непонятный вызов в начале. Поэтому лучше удалить только первый вызов SendMessage, или поменять его параметр с 1 на 0, или изменить переход на другой адрес, чтобы после проверки переменной [0FFA40054h] сразу переходить ко второму вызову. Вариантов много, но результат будет одинаковый.
Где же здесь параметр, равный 1? Всё очень просто — он в регистре r8. Для сокращения кода компилятор никогда не использует прямую пересылку нуля в регистры. Такая команда занимает б байтов: 2 байта код операции, 4 байта — 32-битный ноль. Вместо этого регистр XOR-ится сам с собой, в итоге получается ноль, и это занимает всего 3 байта. После этого r9, который равен нулю, пересылается в r8 с добавлением единицы (выделена зеленым). Эта операция тоже занимает всего 4 байта. Вот эту зеленую 1 нам и надо поменять на 0, и тогда текст не будет портиться.
А теперь найдём эту же процедуру в 32-битной версии блокнота. Если не хочется повторять все те же манипуляции с отладкой, её можно найти простым поиском числа 0C8h.
Как видим, совершенно аналогичный код, только 32-битный. Теперь, чтобы исправить ошибку, осталось только найти это место в ехе-шнике и поменять нужный байт. Перед этим не забудьте стать владельцем файла и дать себе права на его изменение.
Источник
Как при помощи Notepad++ заменить не все найденные слова?
Доброго времени.
Столкнулся с задачкой. Нужно в очень большом количестве текстовых файлов, найти слово «Format» и заменить допустим на слово «Series».
Сложность в том, что нужно заменить слово «Format» только в той строке которая начинается на Column(name=qwerty
и где то по середине строки(в каждом файле по разному) есть слово «Format».
Column(name=qwerty tag=»» band=detail x=’1′ y=’7′ er Format qwe 2v34 gd 3f4g dfgdfgasdf
Column(name=ytrewq tag=»» fgd x=’5′ band=detail y=’7′ Format gdfbvn d 34g fsdg
Column(name=asdfg tag=»» x=’3 band=detail sa y=’2′ Format awerw 23r4 gd 34fgh dfgdfgasdf
Column(name=fdghv tag=»» band=detail y=’6′ x=’1′ Format bvncnmh4 gdfgh 34g dfgdfgasdf
Должно получиться так:
Column(name=qwerty tag=»» band=detail x=’1′ y=’7′ er Series qwe 2v34 gd 3f4g dfgdfgasdf
Column(name=ytrewq tag=»» fgd x=’5′ band=detail y=’7′ Format gdfbvn d 34g fsdg
Column(name=asdfg tag=»» x=’3 band=detail sa y=’2′ Format awerw 23r4 gd 34fgh dfgdfgasdf
Column(name=fdghv tag=»» band=detail y=’6′ x=’1′ Format bvncnmh4 gdfgh 34g dfgdfgasdf
- Вопрос задан более двух лет назад
- 373 просмотра

Поиск:
(Column\(name=qwerty)(.*)(Format)
Замена
\1\2Series
Результат: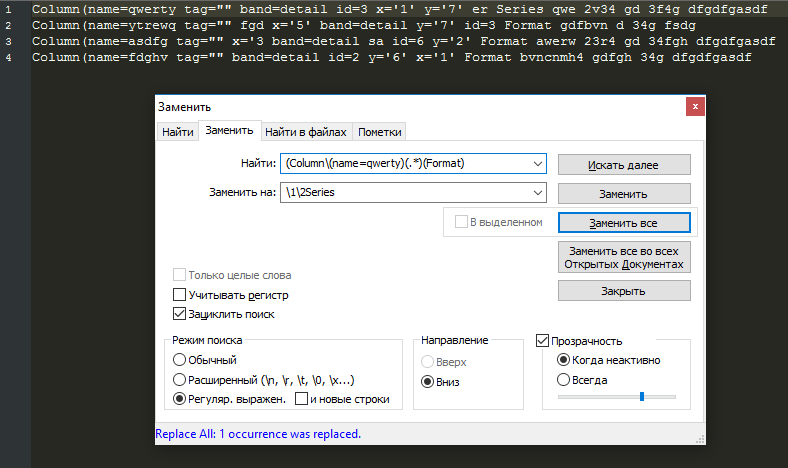
Источник
Notepad++ замена символов, перенос на новую строку
Всем привет! Как-то столкнулся при чтении файлов в редакторе Notepad++ (кто его еще не использует, то настоятельно рекомендую) с необходимостью массового форматирования кода, а именно перенос на новую строку. Так как кода было много и вручную это делать долго и нудно был применен принцип «Автоматизируй это!».
Совет! автоматизируйте рутинные задачи, чтобы оставить время и силы для решения других, более сложных и интересных задач.
Решение
Для того, чтобы в Notepad++ массового выполнить перенос на новую строку необходимо:

- Вызываем окно поиска с помощью Ctrl+F . Режим поиска выбираем «Расширенный». Вкладка «Замена»
- В строке «Найти» пишем что нужно заменить (пример
)
В строке «Заменить на» пишем чего хотим (пример
Справочная информация. Наборы выражений Notepad++
. «Точка» представляет один любой символ;
^ Начало строки;
$ Конец строки;
^$ пустая строка (начало и конец, между которыми пусто);
.+ любая не пустая строка;
\s Пробел;
\S Не Пробел
\w буква, цифра или подчёркивание _;
\d Любая цифра;
\D Любой символ, но не цифра;
7 Любая цифра;
[a-z] Любая буква от a до z (весь латинский набор символов) в нижнем регистре;
[A-Z] Любая буква от A до Z в ВЕРХНЕМ регистре;
[a-zA-Z] или [a-Z] Любая буква от a до z в любом регистре;
* «Повторитель». Означает, что предшествующий символ может повторяться (0 или более раз);
.* Абсолютно любой набор символов. Например, условие
найдет все что между тегами
;
(^.*$) Любой текст между началом и концом строки;
(82*.) ищет любые цифры, в данном случае двухзначные цифры;
\n Ищет символ новой строки;
\r Ищет пустые строки содержащий символы «перевод каретки» ;
^$ Ищет пустые строки
\n\r Ищет пустые строки содержащий символы — символ новой строки и «перевод каретки»
\s Ищет класс пробельных символов. К пробельным символам относятся пробел, символ табуляции, возврат каретки, символ новой строки и символ перевода страницы. То же самое, что и [ \t,\r,\n,\f];
\S Ищет класс не пробельных символов. То же самое, что и [^ \t, \r,\n,\f];
^\s*$ Ищет пустые строки содержащие пробел;
^[ ]*$ Ищет пустые строки содержащие пробел;
^Слово Ищет слово «Слово» в начале строки;
Слово$ Ищет слово «Слово» в конце строки;
\bдол Ищет набор символов «том», только в начале слов, то есть в слове Долина будет найдено, а в слове Подол нет;
дол\b Ищет набор символов «дол», только в конце слов, то есть в слове Долина не будет найдено, а в слове Подол да;
\Bдол\B Ищет набор символов «том», не в начале и не в конце слов, то есть в слове Долина не будет найдено, и в слове Подол нет, а вот в слове Подольск будет найдено;
| — Регулярное выражение, «или». Будет искать то что слева и справа.
Примеры:
Найти (^.*$) Заменить \n\r — находит новую строку и добавляет к ней пустую строку;
Найти (^.*$) Заменить
— находит новую строку и заключает её в теги
;
Найти \n\r Заменить «оставляем пустым» — Удаляет пустые строки
круглые скобки обязательны, иначе найденное будет изменено на заменяемое.
Источник



