- Что делать, если сервер недоступен по сети
- Проверка пинга
- Проверка сетевых настроек сервера
- Диагностика проблем сети с помощью утилиты ip
- Проверка фаервола
- Проверка влияния ПО
- Проверка на наличие сетевых потерь
- Нетривиальные случаи работы с серверами
- Обнаружение неполадок
- Примеры неполадок и способы их устранения
- Сбой в работе сети на сервере
- Плавающая проблема с зависаниями
- Мнимое зависание сервера при установке ОС
- Интересная особенность Dell PowerVault
- Отказ турбин охлаждения
- А где же диски?
- Заключение
Что делать, если сервер недоступен по сети
Рассмотрим случай, когда сервер доступен по VNC, но при этом не пингуется и не реагирует на попытки подключения по ssh. Тут есть несколько сценариев развития событий, о которых мы поговорим далее. Но сначала убедимся, что это наш случай, и проверим, есть ли пинг.
Проверка пинга
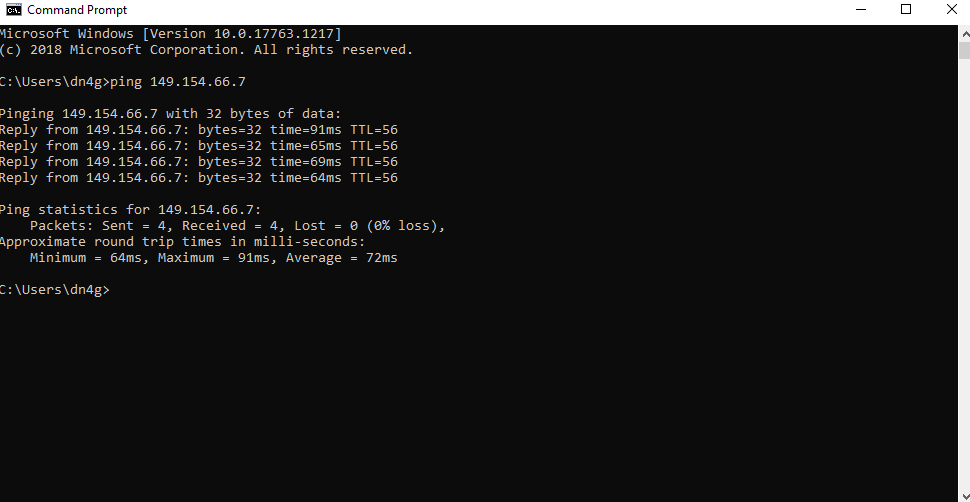
Запустить ping с вашего ПК до IP-адреса вашего сервера можно, например, через CMD : командная строка Windows ( Пуск — Все программы — Стандартные — Командная строка )
Если пинг проходит корректно, то вы увидите статистику переданных пакетов и время ответа, как на скриншоте:
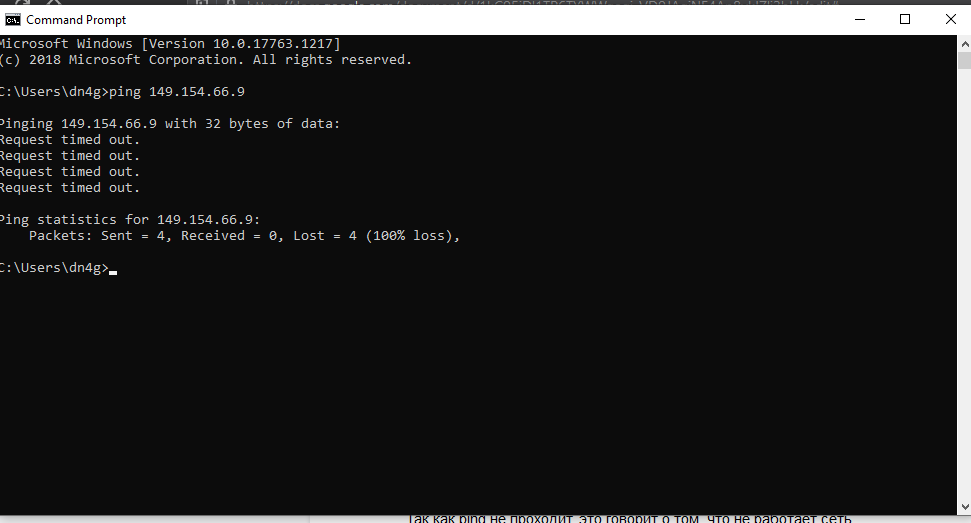
В противном случае появится сообщение об ошибке, что говорит о сетевой недоступности, либо о проблемах с соединением:
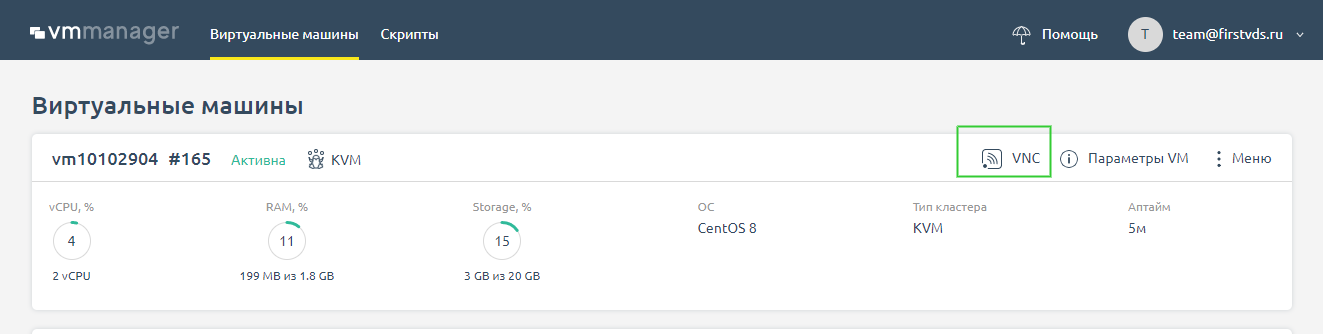
Далее нужно зайти на сам сервер и проверить пинг с сервера до внешних ресурсов, перейдите в панель VMmanager и найдите в верхнем меню значок VNC .

Если вы используете VMmanager 6, то нажмите на кнопку VNC во вкладке Виртуальные машины .
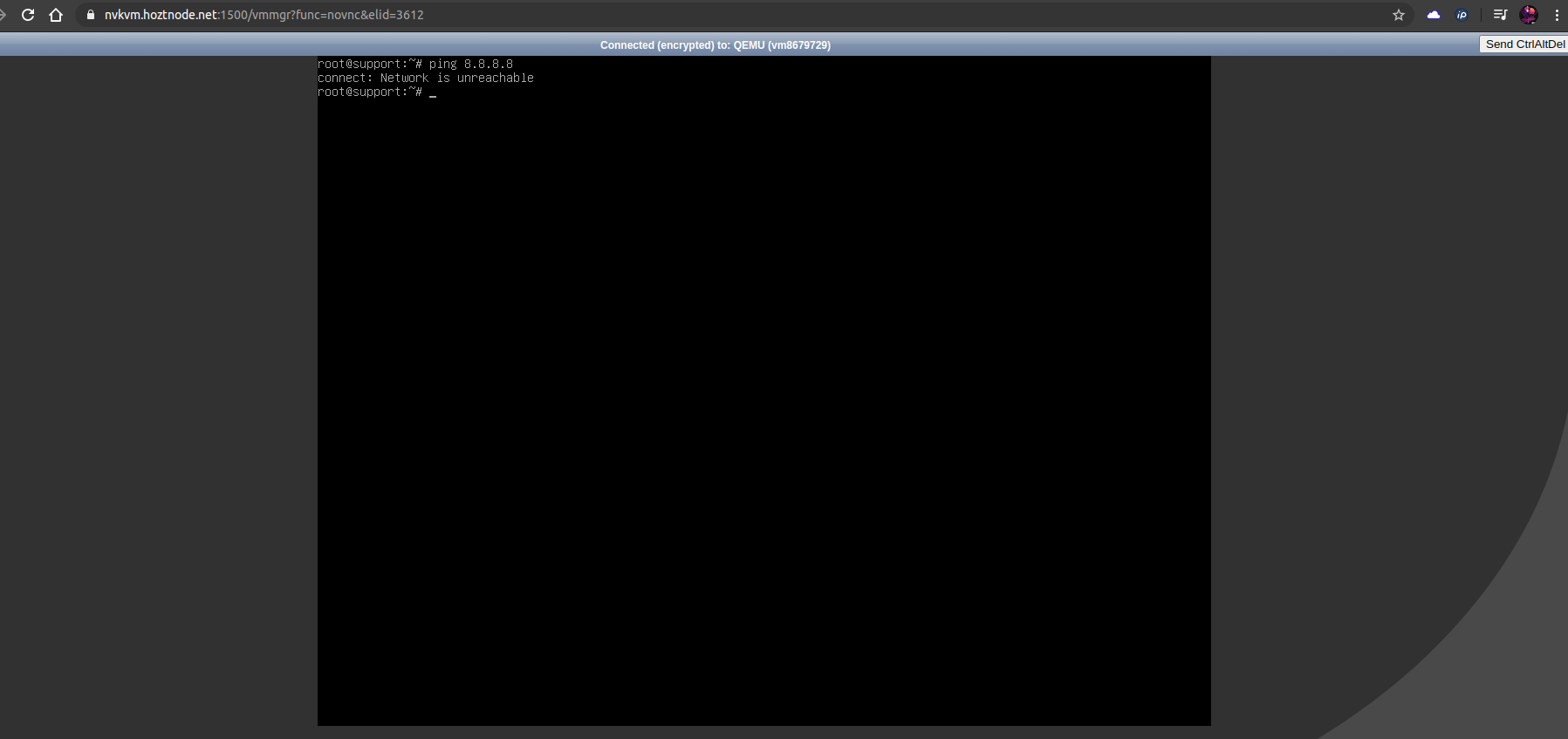
В окне VNC необходимо авторизоваться и запустить ping до любого адреса, например 8.8.8.8 . Если сеть работает, то вы увидите количество переданных пакетов и время, за которое они достигли конечного адреса. Если нет, то придут сообщения вида network unreacheble, connection timeout, либо команда будет просто «висеть» без вывода.
Так как ping не проходит, это говорит о том, что не работает сеть. Поэтому переходим к следующему шагу и идём проверять, в чём может быть проблема.
Проверка сетевых настроек сервера
Первым делом проверим корректность сетевого конфига. Если вы приобрели новый сервер и установили свою операционную систему из образа, могли ошибиться с настройками сети. Но даже для действующего сервера не будет лишним убедиться в том, что настройки в порядке. Узнать, какие сетевые настройки следует использовать для вашей операционной системы, можно в статье «Сетевые настройки в кластерах с технологией VPU».
Диагностика проблем сети с помощью утилиты ip
Диагностировать проблему нам поможет утилита ip — она покажет имя, статус сетевого интерфейса и IP-адреса, которые ему назначены. Утилита установлена во всех современных linux-дистрибутивах.
На сервере с корректными настройками вывод будет таким:
В этом случае, нас интересует блок с названием нашего сетевого интерфейса — в этом случае eth0 (на разных ОС может называться по-разному, например, ens3, eno1).
Здесь прописан наш IP-адрес, маска и шлюз, что можно увидеть в строке:
На наших серверах используется технология VPU , поэтому в качестве сетевого шлюза на серверах используется адрес 10.0.0.1 , а маска подсети /32
Также следует обратить внимание на статус интерфейса. Если его статус DOWN, а не UP, то стоит попробовать запустить интерфейс вручную командой if up eth0 , где вместо eth0 укажите имя вашей сетевой карты. Ранее мы рассмотрели, где можно его найти.
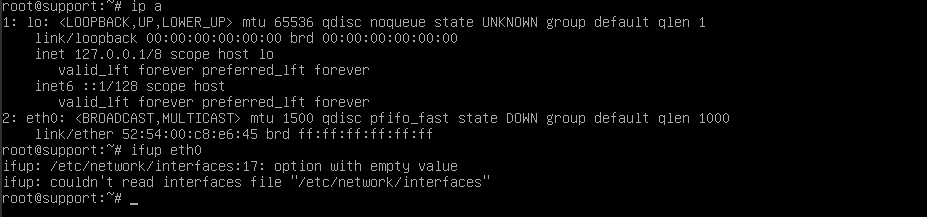
На этом примере видно, что интерфейс не «поднимается» из-за синтаксических ошибок в конфигурационном файле сетевых настроек /etc/network/interfaces .
Также стоит проверить статус службы Network командой systemctl status networking . Если она не запущена, то стоит её запустить командой systemctl start networking . Если служба не запустилась, то, возможно, имеется ошибка в конфигурации, о чём будет сообщено в выводе команды запуска. Вам нужно обратить внимание на строку, которая начинается с Active . Обычно статус запуска службы выделен цветом: красным в случае ошибки и зелёным, если запуск был успешен — как на скриншотах ниже:
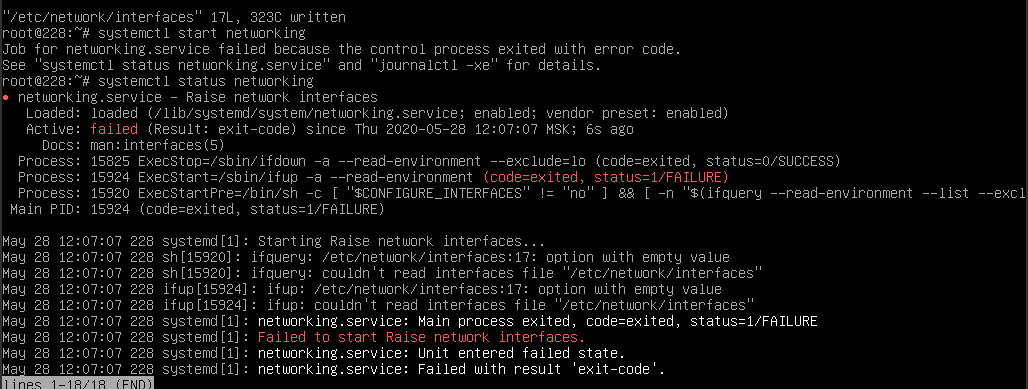
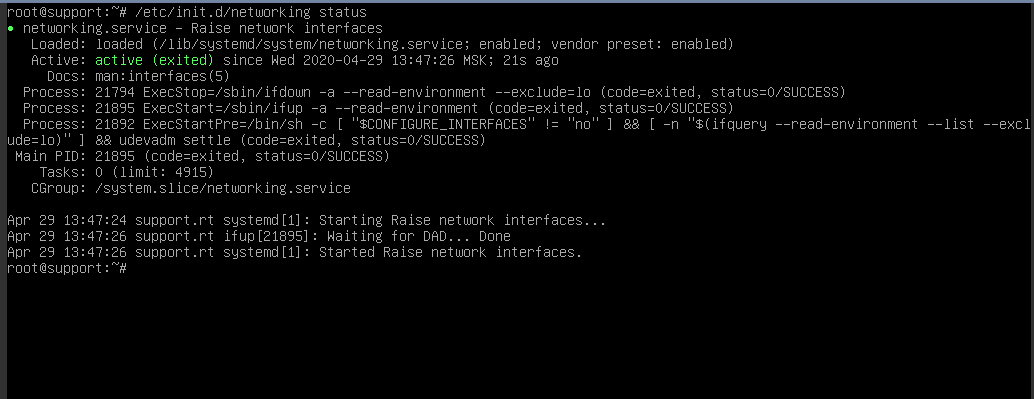
Далее проверяем маршруты. Даже если сетевой интерфейс работает и IP указан верно, без двух маршрутов сеть работать не будет.
Должен быть прописан путь до 10.0.0.1 и он же установлен по умолчанию (дефолтным), как здесь:
Если сеть не заработала, проверяем пинг до шлюза 10.0.0.1 — если он проходит, возможно, проблемы на стороне хостинг-провайдера. Напишите нам в поддержку, разберёмся.
Проверка фаервола
Возможен вариант, что сеть настроена корректно, но трафик блокируется фаерволом внутри самого VDS.
Чтобы это проверить, первым делом смотрим на политики по умолчанию.
Для этого вводим iptables-save и смотрим на первые несколько строк вывода.
В начале мы увидим политику по умолчанию для соединений (цепочек) INPUT , OUTPUT , FORWARD — то есть правила для всех входящих, исходящих и маршрутизируемых соединений. Они имеют статус DROP либо ACCEPT .
Когда все соединения с сервера заблокированы, они имеют статус DROP , и вывод выглядит так:
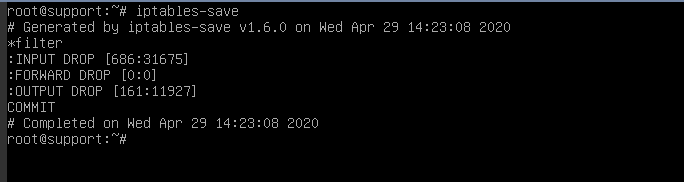
Чтобы исключить влияние фаервола, просматриваем текущие правила с помощью iptables-save и сохраняем их в отдельный файл командой:
Меняем все политики по умолчанию на ACCEPT и сбрасываем все текущие правила командами:
Если после выполнения этих команд сеть появилась, значит проблема была в этом. Поэтому после того, как вы локализовали причину, необходимо разобраться, какое из правил блокирует доступ. Уточним, что при перезагрузке сервера исходные правила восстановятся, либо их можно восстановить командой из ранее сохраненного нами файла
Проверка влияния ПО
Возможен вариант, что установленные на сервере программы (особенно связанные с изменением маршрутизации на сервере, например, OpenVPN, Docker, PPTP) «ломают» работу сети. Чтобы исключить влияние установленного на сервер ПО, можно запустить сервер в режиме восстановления и проверить сеть.
Для этого в панели VMmanager останавливаем VDS и подключаем ISO-образ sysrescueCD через меню Диски :
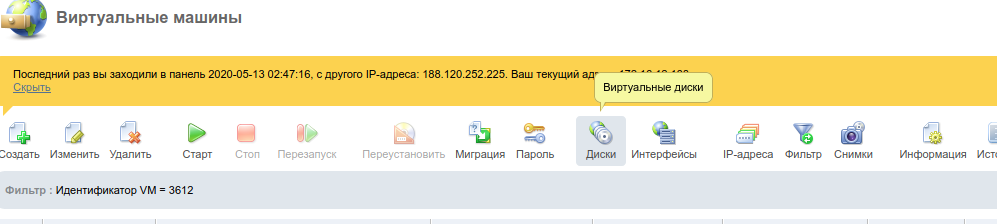
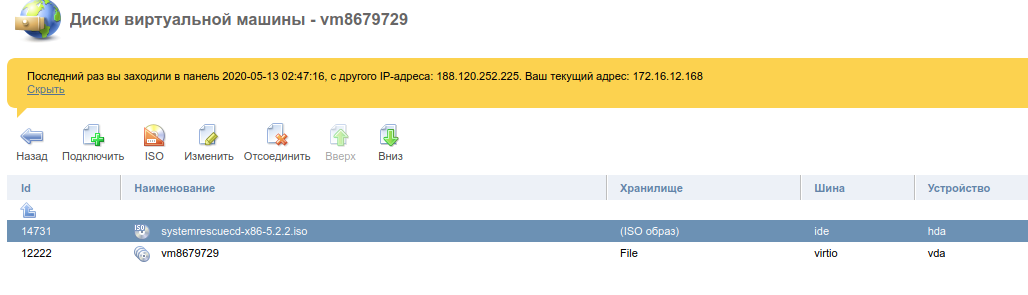
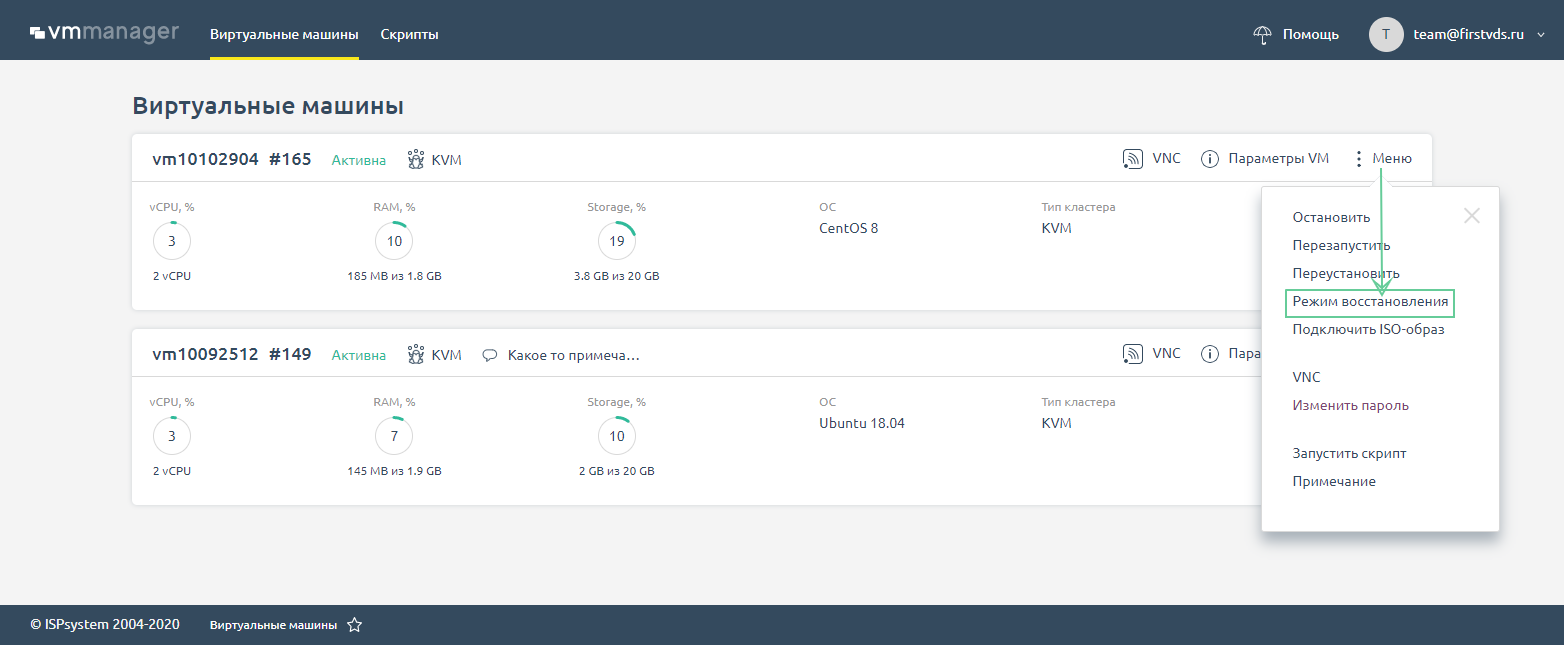
В VMmanager 6 ISO-образ sysrescueCD подключается в Меню сервера по кнопке Режим восстановления на главной странице панели.
После загрузки образа подключаемся по VNC и выполняем команды (в VM6 еще потребуется сначала выбрать образ восстановления в VNC)
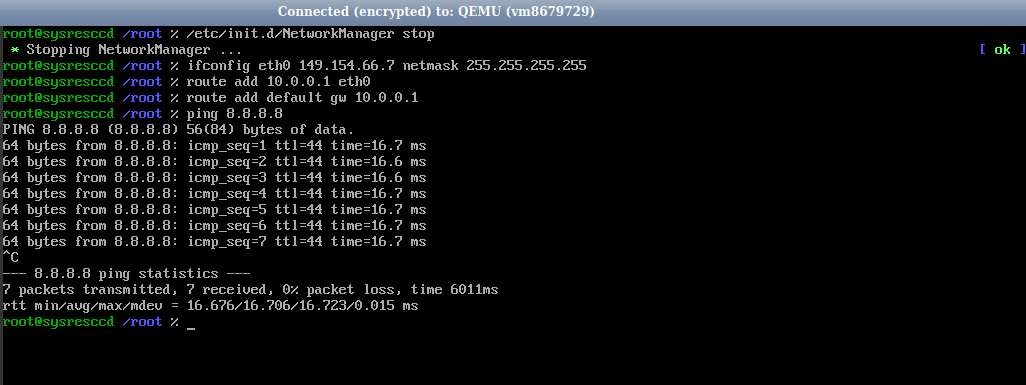
После чего запускаем пинг до 8.8.8.8 . Если он проходит, значит, с сетью на сервере всё благополучно.
Проверка на наличие сетевых потерь
Ещё возможен такой случай, что сеть работает, но наблюдаются потери пакетов по сети, что приводит к долгой загрузке сайтов, долгому ответу сервера и прочим неудобствам.
Для диагностики подойдет утилита mtr . Она совмещает в себе трассировку и пинг, что наглядно показывает, есть ли проблемы с потерей пакетов и на каких узлах (хопах) они проявляются.
Запускаем на сервере mtr до вашего IP, с которого пробуете подключаться, и с сервера — в обратном направлении до вашего адреса :
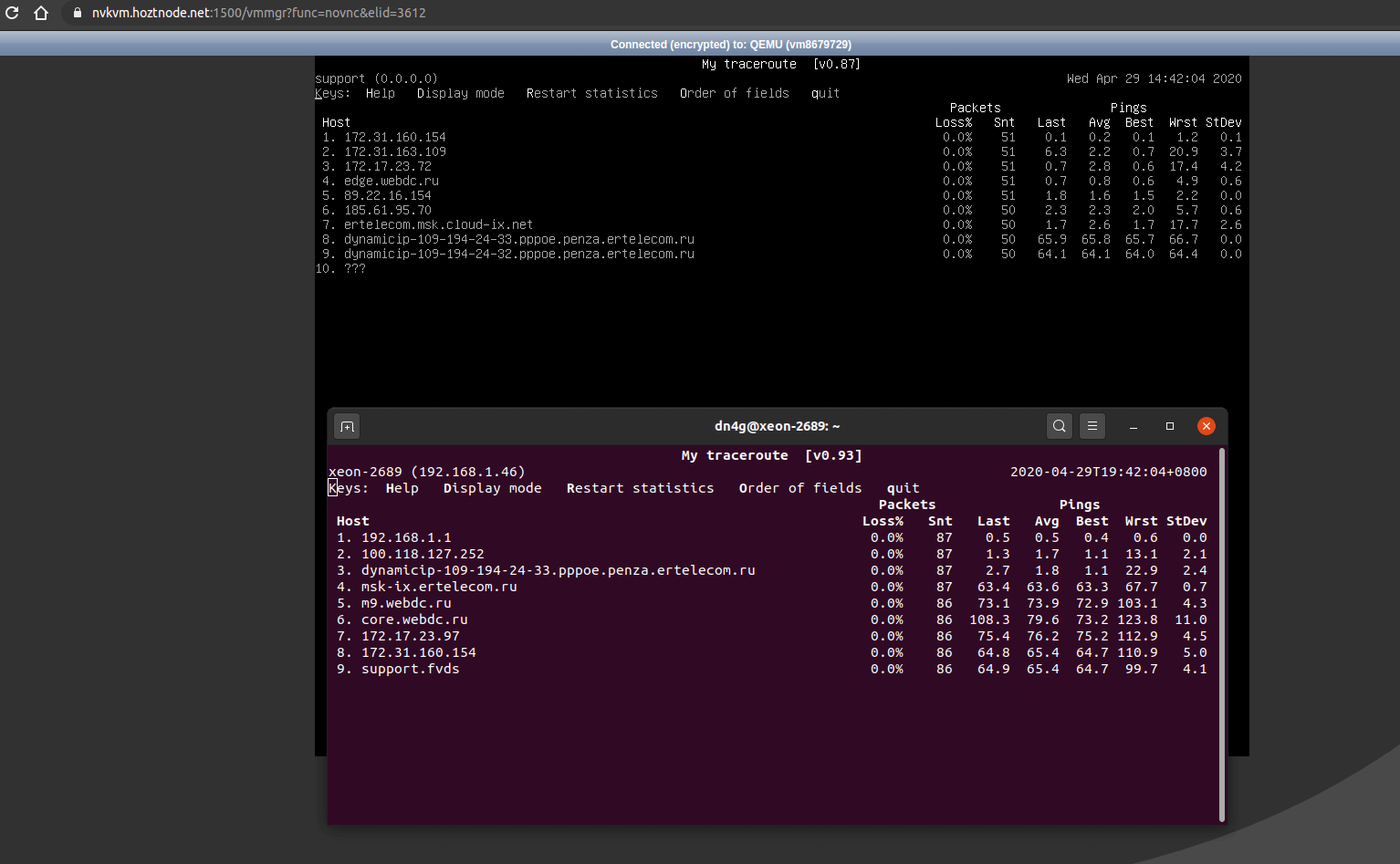
В верхнем окне показана трассировка с сервера до домашнего компьютера, в нижнем обратная, с ПК до сервера. Видно, что потерь нет, пакеты не теряются, пинг стабильный. Так должен выглядеть вывод mtr , если у вас все хорошо.
В случае, если на пути имеются потери, вместо 0.0% на хопах (промежуточных узлах) в столбце Loss будет указан процент потерянных пакетов от соответствующего узла. На примере ниже видно, что потери начинаются на одном из узлов и дальше сохраняются на последующих хопах:

К сожалению, в этом случае проблема уже кроется на стороне провайдеров, через сети которых проходит маршрут до желаемого адреса. Как правило, это носит временный характер, но всегда можно уточнить у техподдержки, нет ли проблем или аварии у провайдера, на чьих сетях наблюдаются потери.
В этой статье мы разобрались, как диагностировать проблемы, связанные с доступностью сервера по сети — от настроек на VDS и параметров фаервола до запуска трассировки при потерях. Если столкнулись с проблемой с доступностью сервера, но ответа в статье не нашли, обратитесь в техническую поддержку — мы всегда поможем.
Источник
Нетривиальные случаи работы с серверами

Любое оборудование, в том числе и серверное, иногда начинает работать непредсказуемо. Абсолютно не важно — новое ли это оборудование, или же оно уже несколько лет работает с полной нагрузкой.
Случаев сбоя и некорректной работы возникает множество и диагностика проблемы зачастую превращается в увлекательную головоломку.
Ниже мы расскажем о некоторых интересных и нетривиальных случаях.
Обнаружение неполадок
Регистрация проблемы чаще всего происходит после обращения клиентов в службу технической поддержки посредством тикет-системы.
В случае обращения клиента, который арендует у нас выделенные серверы фиксированной конфигурации, мы проводим диагностику, чтобы выяснить, что проблема не носит программный характер.
Проблемы программного характера клиенты обычно решают собственными силами, тем не менее, мы в любом случае стараемся предложить помощь наших системных администраторов.
Если становится ясно, что проблема аппаратная (например, сервер не видит часть оперативной памяти), то на этот случай у нас всегда есть в резерве аналогичная серверная платформа.
В случае выявления аппаратной проблемы мы переносим диски со сбойного сервера на резервный и, после небольшой перенастройки сетевого оборудования, выполняется запуск сервера в работу. Таким образом данные не теряются, а время простоя не превышает 20 минут с момента обращения.
Примеры неполадок и способы их устранения
Сбой в работе сети на сервере
Существует вероятность, что после переноса дисков со сбойного сервера на резервный перестанет работать сеть на сервере. Это обычно происходит в случае использования операционных систем семейства Linux, например Debian или Ubuntu.
Дело в том, что при первоначальной установке операционной системы, MAC-адреса сетевых карт записываются в специальный файл, расположенный по адресу: /etc/udev/rules.d/70-persistent-net.rules.
При старте операционной системы этот файл сопоставляет имена интерфейсов MAC-адресам. При замене сервера на резервный, MAC-адреса сетевых интерфейсов уже не совпадают, что и приводит к неработоспособности сети на сервере.
Для решения проблемы необходимо удалить указанный файл и перезапустить сетевой сервис, либо перезагрузить сервер.
Операционная система, не найдя этого файла, автоматически сгенерирует аналогичный и сопоставит интерфейсы уже с новыми MAC-адресами сетевых карт.
Перенастройки IP-адресов после этого не требуется, сеть сразу начнет работать.
Плавающая проблема с зависаниями
Однажды к нам на диагностику поступил сервер с проблемой случайных зависаний в процессе работы. Проверили логи BIOS и IPMI — пусто, никаких ошибок. Поставили на стресс-тестирование, нагрузив все ядра процессора на 100%, с одновременным контролем температуры — завис намертво через 30 минут работы.
При этом процессор работал штатно, значения температуры не превышали стандартных при нагрузке, все кулеры были исправны. Стало ясно, что дело не в перегреве.
Далее следовало исключить вероятные сбои модулей оперативной памяти, поэтому поставили сервер на тест памяти с помощью достаточно популярного Memtest86+. Минут через 20 сервер ожидаемо завис, выдав ошибки по одному из модулей оперативной памяти.
Заменив модуль на новый, мы поставили сервер на тест повторно, однако нас ждало фиаско — сервер вновь завис, выдав ошибки уже по другому модулю ОЗУ. Заменили и его. Еще один тест — еще раз завис, вновь выдав ошибки по оперативной памяти. Внимательный осмотр слотов ОЗУ не выявил никаких дефектов.
Оставался один возможный виновник проблемы — центральный процессор. Дело в том, что контроллер оперативной памяти расположен именно внутри процессора и именно он мог давать сбой.
Сняв процессор, обнаружили катастрофу — один пин сокета был сломан в верхней части, обломанный кончик пина буквально прикипел к контактной площадке процессора. В итоге, когда на сервере не было нагрузки, все работало адекватно, но при увеличении температуры процессора контакт нарушался, тем самым прекращая нормальную работу контроллера оперативной памяти, что и вызывало зависания.
Окончательно проблема решилась заменой материнской платы, поскольку восстановить сломавшийся пин сокета нам, увы, не под силу, и это уже задача для сервисного центра.
Мнимое зависание сервера при установке ОС
Достаточно забавные случаи возникают, когда производители оборудования начинают менять архитектуру аппаратной части, отказываясь от поддержки старых технологий в пользу новых.
К нам обратился пользователь с жалобой на зависание сервера при попытке установки операционной системы Windows Server 2008 R2. После успешного запуска инсталлятора, сервер прекращал реагировать на мышь и клавиатуру в KVM-консоли. Для локализации проблемы подключили к серверу физическую мышь и клавиатуру — все то же самое, инсталлятор запускается и перестает реагировать на устройства ввода.
На тот момент этот сервер у нас был одним из первых на базе материнской платы X11SSL-f производства Supermicro. В настройках BIOS был один интересный пункт Windows 7 install, выставленный в Disable. Поскольку Windows 7, 2008 и 2008 R2 разворачиваются на одном и том же инсталляторе, выставили этот параметр в Enable и чудесным образом мышь и клавиатура наконец-то заработали. Но это было лишь только начало эпопеи с установкой операционной системы.
На моменте выбора диска для установки ни одного диска не отображалось, более того, выдавалась ошибка необходимости установки дополнительных драйверов. Операционная система устанавливалась с USB-флешки и быстрый поиск в интернете показал, что такой эффект возникает, если программа установки не может найти драйвера для контроллера USB 3.0.
Википедия сообщила, что проблема решается отключением в BIOS поддержки USB 3.0 (XHCI-контроллера). Когда мы открыли документацию к материнской плате, нас ожидал сюрприз — разработчики решили полностью отказаться от контроллера EHCI (Enhanced Host Controller Interface) в пользу XHCI (eXtensible Host Controller Interface). Иными словами, все порты USB на этой материнской плате являются портами USB 3.0. И если отключить контроллер XHCI, то мы этим самым отключим и устройства ввода, сделав невозможным работу с сервером и соответственно установку операционной системы.
Поскольку серверные платформы не были оборудованы приводами для чтения CD/DVD дисков, единственным решением проблемы стало интегрирование драйверов непосредственно в дистрибутив операционной системы. Только интегрировав драйвера контроллера USB 3.0 и пересобрав установочный образ, мы смогли установить Windows Server 2008 R2 на этот сервер, а этот случай вошел в нашу базу знаний, чтобы инженеры не тратили лишнее время на бесплодные попытки.
Интересная особенность Dell PowerVault
Еще забавнее бывают случаи, когда клиенты привозят нам оборудование на размещение, а оно ведет себя не так, как ожидается. Именно так и произошло с дисковой полкой линейки Dell PowerVault.
Устройство представляет собой систему хранения данных c двумя дисковыми контроллерами и сетевыми интерфейсами для работы по протоколу iSCSI. Помимо этих интерфейсов присутствует MGMT-порт для удаленного управления.
Среди наших услуг для размещенного оборудования как раз есть специальная услуга «Дополнительный порт 10 Мбит/с», которую заказывают в случае необходимости подключения средств удаленного управления сервером. Эти средства носят разные названия:
- «iLO» у Hewlett-Packard;
- «iDrac» у Dell;
- IPMI у Supermicro.
Функционал у них приблизительно одинаков — мониторинг состояния сервера и доступ к удаленной консоли. Соответственно большая скорость канала им не требуется — 10 Мбит/с вполне достаточно для комфортной работы. Именно эта услуга и была заказана клиентом. Мы проложили соответствующую медную кроссировку, и настроили порт нашего сетевого оборудования.
Для ограничения скорости порт просто настраивается как 10BASE-T и включается в работу, имея максимальную скорость в 10 Мбит/с. После того, как все было готово — мы подключили MGMT-порт дисковой полки, но клиент почти сразу сообщил, что у него ничего не работает.
Проверив состояние порта коммутатора, мы обнаружили неприятную надпись «Physical link is down». Такая надпись говорит, что имеется проблем с физическим соединением между коммутатором и подключенным в него клиентским оборудованием.
Плохо обжатый коннектор, сломанный разъем, перебитые жилы в кабеле — вот небольшой перечень проблем, которые приводят именно к отсутствию линка. Разумеется, наши инженеры сразу взяли тестер витой пары и проверили соединение. Все жилы идеально прозванивались, оба конца кабеля были обжаты идеально. К тому же, включив в этот кабель тестовый ноутбук, мы получили как и положено соединение со скоростью 10 Мбит/с. Стало ясно, что проблема на стороне оборудования клиента.
Поскольку мы всегда стараемся помочь нашим клиентам в решении проблем, решили разобраться, что именно вызывает отсутствие линка. Внимательно изучили разъем порта MGMT — все в порядке.
Нашли на сайте производителя оригинальную инструкцию по эксплуатации, чтобы уточнить — возможно ли со стороны программного обеспечения «погасить» данный порт. Однако такой возможности не предусматривалось — порт в любом случае поднимался автоматически. Несмотря на то, что подобное оборудование должно всегда поддерживать Auto-MDI(X) — иными словами правильно определять какой кабель включен: обычный или кроссовер, мы эксперимента ради обжали кроссовер и включили в тот же порт коммутатора. Пробовали принудительно выставлять параметр дуплекса на порту коммутатора. Эффект был нулевой — линка не было и идеи уже заканчивались.
Тут кто-то из инженеров высказал абсолютно противоречащее здравому смыслу предположение, что оборудование не поддерживает 10BASE-T и будет работать только на 100BASE-TX или даже на 1000BASE-X. Обычно любой порт, даже на самом дешевом устройстве совместим с 10BASE-T и вначале предположение инженера отмели как “фантастику”, но от безысходности решили попробовать переключить порт в 100BASE-TX.
Нашему удивлению не было предела, линк мгновенно поднялся. Чем именно обусловлено отсутствие поддержки 10BASE-T на порту MGMT остается загадкой. Такой случай — очень большая редкость, но имеет место быть.
Клиент был удивлен не меньше нашего и очень благодарил за решение проблемы. Соответственно ему так и оставили порт в 100BASE-TX, ограничив скорость на порту непосредственно с помощью встроенного механизма ограничения скорости.
Отказ турбин охлаждения
Как-то раз к нам приехал клиент, попросил снять сервер и вынести его в сервисную зону. Инженеры все сделали и оставили его наедине с оборудованием. Прошел час, второй, третий — клиент все время запускал/останавливал сервер и мы поинтересовались, в чем же заключается проблема.
Оказывается, что у сервера производства Hewlett-Packard отказало две турбинки охлаждения из шести. Сервер при этом включается, выдает ошибку по охлаждению и сразу выключается. При этом на сервере располагается гипервизор с критичными сервисами. Для восстановления штатной работы сервисов требовалось выполнить срочную миграцию виртуальных машин на другую физическую ноду.
Решили клиенту помочь следующим образом. Обычно сервер понимает, что с вентилятором охлаждения все хорошо, просто считывая количество оборотов. При этом, разумеется, инженеры Hewlett-Packard сделали все, чтобы нельзя было заменить оригинальную турбинку аналогом — нестандартный коннектор, нестандартная распиновка.
Оригинал такой детали стоит около $100 и ее нельзя просто так пойти и купить — надо заказывать из-за рубежа. Благо в интернете обнаружили схему с оригинальной распиновкой и выяснили, что один из пинов как раз отвечает за считывание количества оборотов двигателя в секунду.
Дальнейшее было делом техники — взяли пару проводов для прототипирования (волей случая оказались под рукой — некоторые наши инженеры увлекаются Arduino) и просто соединили пины от соседних рабочих турбинок с коннекторами вышедших из строя. Сервер запустился и клиенту наконец-то удалось выполнить миграцию виртуальных машин и запустить сервисы в работу.
Разумеется, что все это было выполнено исключительно под ответственность клиента, тем не менее в итоге такой нестандартный ход позволил сократить простой до минимума.
А где же диски?
В некоторых случаях причина проблемы порой настолько нетривиальна, что на ее поиск уходит очень большое количество времени. Так и получилось, когда один из наших клиентов пожаловался на случайный отвал дисков и зависание сервера. Аппаратная платформа — Supermicro в корпусе 847 (форм-фактора 4U) с корзинами для подключения 36-ти дисков. В сервере было установлено три одинаковых RAID-контроллера Adaptec, к каждому подключено по 12 дисков. В момент возникновения проблемы, сервер переставал видеть случайное количество дисков и зависал. Сервер вывели из продакшн и приступили к диагностике.
Первое, что удалось выяснить — диски отваливались только на одном контроллере. При этом «выпавшие диски» исчезали из списка в родной утилите управления Adaptec и заново там появлялись только при полном отключении питания сервера и последующем подключении. Первое, что пришло на ум — программное обеспечение контроллера. На всех трех контроллерах стояли немного разные прошивки, поэтому было решено на всех контроллерах установить одну версию прошивки. Выполнили, погоняли сервер в режимах максимальной нагрузки — все работает как положено. Пометив проблему как решенную, сервер отдали клиенту обратно в продакшн.
Через две недели снова обращение с той же проблемой. Было решено заменить контроллер на аналогичный. Выполнили, прошили, подключили, поставили на тесты. Проблема осталась — через пару дней выпали все диски уже на новом контроллере и сервер благополучно завис.
Переустановили контроллер в другой слот, заменили бэкплейн и SATA-кабели от контроллера до бэкплейна. Неделя тестов и снова диски выпали — сервер вновь завис. Обращение в поддержку Adaptec результатов не принесло — они проверили все три контроллера и проблем не обнаружили. Заменили материнскую плату, пересобрав платформу чуть ли не с нуля. Все, что вызывало малейшие сомнения заменили на новое. И проблема вновь проявилась. Мистика да и только.
Проблему удалось решить случайно, когда стали проверять в отдельности каждый диск. При определенной нагрузке один из дисков начинал стучать головами и давал короткое замыкание на порт SATA, при этом какая-либо аварийная индикация отсутствовала. Контроллер при этом переставал видеть часть дисков и вновь начинал их опознавать только при переподключении по питанию. Вот так один единственный сбойный диск выводил из строя всю серверную платформу.
Заключение
Конечно, это лишь малая часть интересных ситуаций, которые были решены нашими инженерами. Некоторые проблемы «отловить» достаточно непросто, особенно когда в логах нет никаких намеков на произошедший сбой. Зато любые подобные ситуации стимулируют инженеров детально разбираться в устройстве серверного оборудования и находить самые разнообразные решения проблем.
Вот такие забавные случаи были в нашей практике.
А с какими сталкивались вы? Добро пожаловать в комментарии.
Источник



